· roofline 위의 MobileNet-v2, 그리고 실무 경계
목차
지금까지 트래픽을 세고, 어디서 늘고, 파라미터와 어떻게 다른지 봤다. 이 장은 그 모든 수치가 칩 위에서 어떤 성능을 뜻하는지 묶는다. 00장에서 정의한 roofline에 MobileNet-v2를 얹어 보고, INT8 양자화가 왜 도움이 되는지, depthwise의 연산강도가 왜 그렇게 낮은지를 풀고, 끝으로 이 책이 센 66 MB가 실무에서 줄어드는 경계를 짚는다.
05.1 모델은 roofline 어디에 앉나
00장에서 roofline의 변곡점(ridge)을 정의했다. 연산강도가 I = π/β보다 낮으면 대역폭이 병목인 memory-bound, 높으면 연산이 병목인 compute-bound다. 실제 칩의 ridge는 보통 수십에서 수백 MAC/byte에 있다. 여기서는 ridge가 약 85 MAC/byte인 칩을 예로 든다.
이제 MobileNet-v2의 각 단계 연산강도를 그 위에 올려놓는다. 02장에서 센 값들이다.
| 단계 | 연산강도 (MAC/byte) |
|---|---|
| 분류기 FC | 0.25 |
| depthwise | 1.1 |
| 전체 모델 (FP32) | 4.3 |
| expand·project 1×1 | 5~9 |
| 전체 모델 (INT8) | 17.3 |
가장 높은 값이 INT8 전체 모델의 17.3이다. 그것조차 ridge 85보다 한참 낮다. 곧 MobileNet-v2의 어느 단계도 compute-bound가 아니다. 전부 memory-bound다. 곱셈이 적은 가벼운 모델인데도 그렇다. 곱셈을 더 빨리 하는 연산기를 달아도 빨라지지 않고, 메모리를 더 빨리 읽어 와야 빨라진다.
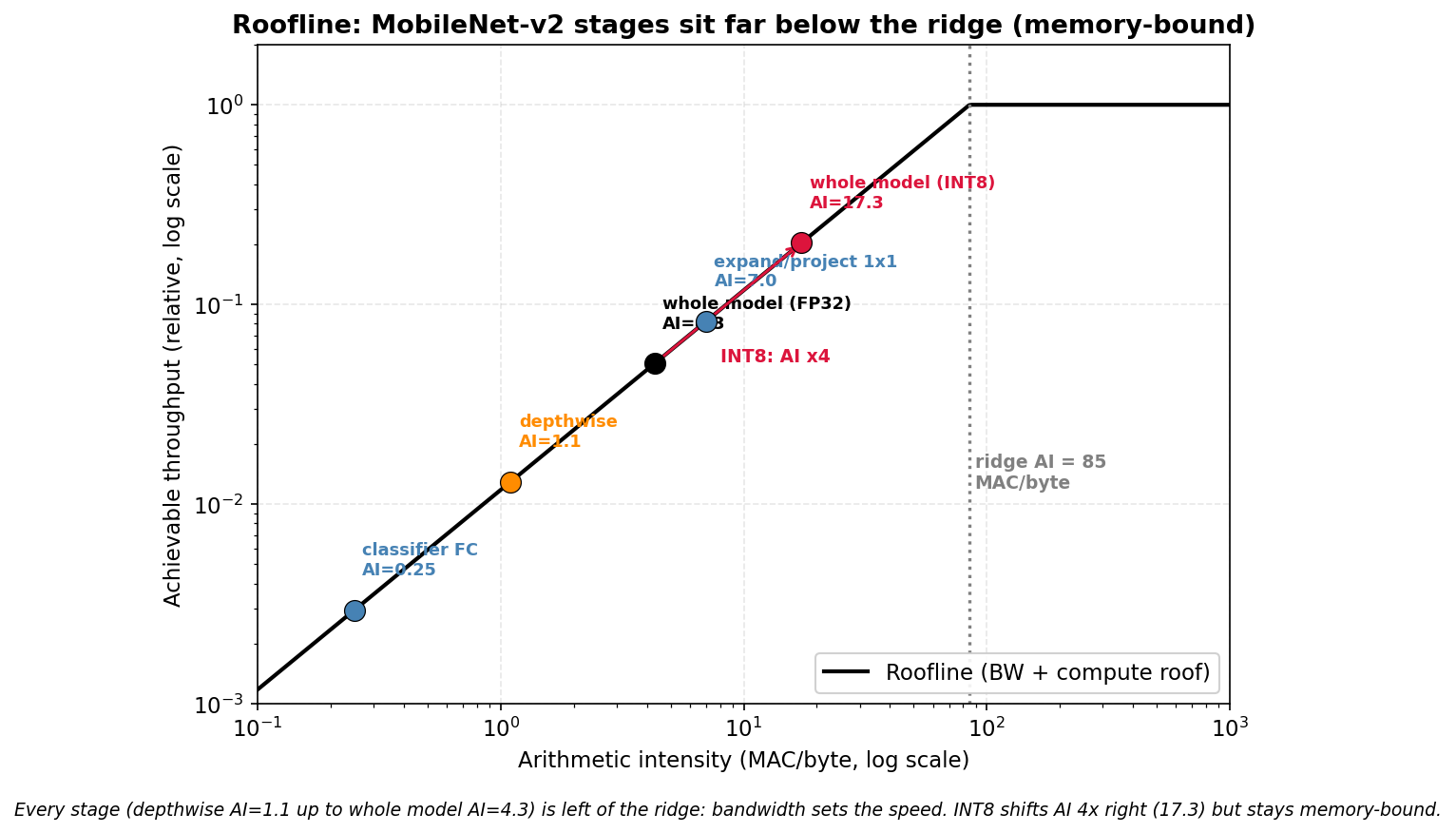
비스듬한 직선이 대역폭 천장이고, 오른쪽 끝의 평평한 선이 연산 천장이다. 둘이 만나는 곳이 ridge다. 모든 단계 점이 ridge 왼쪽 비탈에 찍혀 있다. 이 비탈 위에서는 성능이 연산강도에 비례한다(P = β · I). 그래서 연산강도를 오른쪽으로 미는 일, 곧 같은 연산을 더 적은 바이트로 하는 일이 곧 속도다.
05.2 depthwise는 왜 연산강도가 바닥인가
depthwise 단계의 연산강도가 1.1로 가장 낮았다. 분류기를 빼면 모델에서 가장 낮은 축이다. 왜 그런지를 풀면 트래픽 전체의 그림이 닫힌다.
depthwise 합성곱은 입력 채널마다 독립된 커널 하나를 적용한다. 채널 간에 섞지 않는다. 그래서 가중치 재사용이 거의 없다. 표준 합성곱과 대 보면 차이가 또렷하다. 표준 합성곱은 한 출력 채널의 가중치 집합이 모든 공간 위치에서 쓰이고, 게다가 모든 입력 채널과 곱해진다. 가중치 수는 (입력 채널 × 출력 채널)이고, 그 가중치로 하는 곱셈은 그보다 feature map 크기만큼 더 많다. 한 번 읽은 가중치로 아주 많은 곱셈을 한다.
depthwise는 다르다. 채널당 커널이 3×3=9개뿐이고, 그 커널로 하는 곱셈은 그 채널의 feature map 위에서만이다. 채널 간 합산이 없으니 곱셈 수가 적다. 가중치 한 바이트로 할 수 있는 일이 적다는 뜻이다. 정리하면 이렇다(Howard et al. 2017의 비용 공식에서 나온다).
가중치당 곱셈 ≈ feature map 크기 (= D_F²)
곧 가중치 한 벌로 하는 곱셈이 feature map의 픽셀 수만큼이다. feature map이 작아지는 후반 레이어에서는 이 값마저 더 작아진다. 그러니 연산강도(MAC/byte)가 낮아진다. 블록 A에서 1.12, 블록 B에서 1.03이었던 까닭이다. 일은 적은데 옮길 활성값은 크다. 02장에서 본 대로, depthwise는 expand가 부풀린 넓은 텐서를 통째로 읽고 쓴다. 적은 일에 큰 트래픽이니 I = W/Q가 바닥으로 떨어진다.
이것이 MobileNet 계열이 안고 있는 구조적 사정이다. depthwise separable 합성곱은 곱셈을 표준 합성곱의 8~9분의 1로 줄여 모델을 가볍게 만든다(Howard et al. 2017). 그 대가로 연산강도가 낮아져 memory-bound로 기운다. 곱셈을 줄인 바로 그 설계가 모델을 대역폭에 묶는다.
05.3 INT8 — 바이트를 줄여 연산강도를 끌어올린다
memory-bound 모델을 빠르게 하는 직접적인 길은 옮길 바이트를 줄이는 것이다. INT8 양자화가 그 일을 한다. 숫자를 32비트 대신 8비트로 저장하면, 모든 가중치와 활성값이 4분의 1 byte가 된다.
| 구분 | FP32 (4 byte) | INT8 (1 byte) |
|---|---|---|
| 전체 트래픽 | 66.18 MB | 16.55 MB |
| 가중치 | 13.24 MB | 3.31 MB |
| 활성값 | 52.94 MB | 13.24 MB |
| 곱셈(MAC) | 301 M | 301 M (불변) |
| 전체 연산강도 | 4.3 MAC/byte | 17.3 MAC/byte |
트래픽이 정확히 4분의 1이 된다. 곱셈 수는 자료형과 무관하게 301 M 그대로다. 일은 그대로인데 트래픽만 4분의 1이 되니, 연산강도는 정확히 4배가 된다. 4.3에서 17.3으로 오른다. roofline에서 점이 오른쪽으로 옮겨 가고, memory-bound 비탈 위에서는 성능이 연산강도에 비례하므로 그만큼 빨라진다.
다만 17.3도 ridge 85보다는 낮다. INT8로 옮겨도 여전히 memory-bound다. 양자화는 트래픽을 줄여 도움을 주지만, 그것만으로 이 모델을 compute-bound로 만들지는 못한다. 그래도 옮길 바이트를 4분의 1로 줄인 효과는 분명하다.
05.4 66 MB는 상한이다 — fusion·tiling·in-place
이 책이 센 66 MB는 가장 단순하고 가장 큰 값이다. 활성값을 "한 번 쓰고 한 번 읽음"으로 셌고, 모든 중간 텐서가 주 메모리(DRAM)를 왕복한다고 봤다. 실제 칩의 컴파일러는 이 상한을 줄인다.
- operator fusion(연산 융합) — expand에서 depthwise를 거쳐 project까지를 한 커널로 묶으면, 중간 텐서를 DRAM에 쓰지 않고 온칩 SRAM에 잠시 머물게 할 수 있다. 그러면 그 텐서의 쓰기와 읽기(블록 A에서 expand 출력 1.7 MB의 왕복 등)가 외부 트래픽에서 빠진다.
- tiling(타일링) — 큰 텐서를 SRAM에 맞게 조각으로 나눠 재사용하면 입력을 다시 읽는 양을 줄인다.
- in-place 활성함수 — ReLU6 같은 활성함수는 값을 제자리에서 덮어쓰므로 별도 트래픽을 만들지 않는다. 이 책의 셈은 이미 이를 반영해 활성함수 트래픽을 0으로 뒀다.
그래서 실제로 칩이 옮기는 바이트는 66 MB보다 작을 수 있다. 재사용 정도를 1보다 작은 계수로 곱한 값이다. 정확한 값은 실제 모델을 프로파일러에 통과시켜야 안다.
그러나 구조적 결론은 fusion으로도 안 뒤집힌다. 가중치는 어차피 한 번은 읽어야 하니 줄지 않고, 활성값 비중이 압도적이며, depthwise의 연산강도가 바닥이라는 사실은 그대로다. 이 책의 셈은 보수적인 상한으로서 "어느 항이 트래픽을 지배하는가"를 정확히 가른다. 그 판정이 fusion 여부와 무관하다는 점이 중요하다.
05.5 정리
MobileNet-v2의 모든 단계는 roofline의 ridge보다 한참 낮은 곳에 앉아 memory-bound다. depthwise는 채널당 커널이 하나라 재사용이 없어 연산강도가 1 언저리로 바닥이다. INT8은 바이트를 4분의 1로 줄여 연산강도를 4배로 올리지만 여전히 ridge 아래다. 실무의 fusion·tiling은 외부 트래픽을 줄이지만, 활성값 지배와 depthwise 바닥이라는 결론은 바꾸지 못한다. 다음 장에서 세 질문의 답을 한자리에 모은다.