· MobileNet-v2를 한 바이트씩 세기
목차
01장에서 레이어 하나를 셀 수 있게 됐다. 이제 실제 모델을 통째로 센다. MobileNet-v2는 모바일 기기에서 쓰려고 만든 합성곱 신경망이다(Sandler et al. 2018). 파라미터가 약 3.4 M개, 곱셈-누산이 약 300 M번으로 가벼운 축에 든다. 바로 그 "가벼운" 모델이 메모리에서는 얼마나 무거운지를 이 장에서 본다.
먼저 모델의 뼈대와 블록 구조를 익히고, 대표 블록 두 개를 완전 분해한다. 전체 트래픽 66 MB를 쌓는 일은 이어지는 02a장에서 한다.
2.1 MobileNet-v2의 뼈대
MobileNet-v2(width 1.0, 입력 224×224×3)는 다음 채널 흐름을 따른다.
32 → 16 → 24 → 32 → 64 → 96 → 160 → 320 → 1280
입력 사진은 224×224다. 앞쪽 stem 합성곱이 해상도를 절반으로 줄이며 채널을 32개로 만든다. 그 뒤로 bottleneck 블록들이 줄지어 해상도를 단계마다 절반으로 줄이고 채널을 늘린다. 마지막에 1×1 합성곱이 채널을 1280개로 키우고, 평균 풀링과 분류기 전결합층이 1000개 클래스 점수를 낸다. 단계별 스펙은 원논문 Table 2에 있다(Sandler et al. 2018).
| # | 입력 (해상도² × 채널) | 연산 | t | 출력 채널 c | 반복 n | 첫 stride s |
|---|---|---|---|---|---|---|
| 0 | 224² × 3 | conv2d 3×3 (stem) | – | 32 | 1 | 2 |
| 1 | 112² × 32 | bottleneck | 1 | 16 | 1 | 1 |
| 2 | 112² × 16 | bottleneck | 6 | 24 | 2 | 2 |
| 3 | 56² × 24 | bottleneck | 6 | 32 | 3 | 2 |
| 4 | 28² × 32 | bottleneck | 6 | 64 | 4 | 2 |
| 5 | 14² × 64 | bottleneck | 6 | 96 | 3 | 1 |
| 6 | 14² × 96 | bottleneck | 6 | 160 | 3 | 2 |
| 7 | 7² × 160 | bottleneck | 6 | 320 | 1 | 1 |
| 8 | 7² × 320 | conv2d 1×1 | – | 1280 | 1 | 1 |
| 9 | 7² × 1280 | avgpool 7×7 | – | – | 1 | – |
| 10 | 1² × 1280 | conv2d 1×1 (분류기) | – | 1000 | – | – |
표의 한 행은 같은 모양의 블록을 n번 반복한 묶음이다. 묶음의 첫 블록만 stride s로 해상도를 줄이고, 나머지는 stride 1로 해상도를 유지한다. t는 확장계수(expansion factor)다. 그 뜻은 다음 절에서 푼다.
블록을 몇 개로 세는가. 같은 모델을 두고 "블록이 17개"라고도 "19개"라고도 한다. 차이는 무엇을 한 블록으로 묶느냐일 뿐이다. 위 표의 반복 횟수
n을 모두 더하면 1+2+3+4+3+3+1 = 17개의 bottleneck 블록이다. 이 책은 이 17개를 기준으로 센다. 원논문이 다른 방식으로 세면 19개가 되지만, 채널·곱셈·파라미터의 총합은 어느 쪽이든 같다. 헷갈리지 않도록 이 책은 줄곧 "bottleneck 블록 17개"로 부른다.
2.2 bottleneck 블록의 안쪽 — inverted residual
bottleneck 블록 하나는 세 단계로 이루어진다. 이 구조에 inverted residual이라는 이름이 붙어 있다.
| 단계 | 연산 | 텐서 변화 (공간 × 채널) |
|---|---|---|
| expand | 1×1 합성곱, ReLU6 | h × w × k → h × w × (t·k) |
| depthwise | 3×3 채널별 합성곱, stride s, ReLU6 | h × w × (t·k) → (h/s) × (w/s) × (t·k) |
| project | 1×1 합성곱 (선형, 활성함수 없음) | (h/s) × (w/s) × (t·k) → (h/s) × (w/s) × k′ |
입력은 채널이 좁은 텐서다(채널 k개). expand 단계가 1×1 합성곱으로 채널을 t배로 부풀린다. 주 실험에서 t는 6이다. 그러면 채널이 t·k개인 넓은 텐서가 된다. depthwise 단계가 이 넓은 텐서에 채널별 3×3 합성곱을 건다. 채널 수는 그대로 두고 stride로 해상도만 줄인다. project 단계가 다시 1×1 합성곱으로 채널을 좁은 k′개로 되돌린다. 이때는 활성함수를 붙이지 않는다(linear bottleneck).
좁은 채널에서 넓은 채널로 부풀렸다가 다시 좁히는 구조다. stride가 1이고 입출력 채널이 같으면(k = k′) 입력을 출력에 그대로 더하는 지름길(skip)을 둔다. 이름이 "inverted"인 까닭은 보통의 residual 블록이 넓은 채널 사이에 좁은 병목을 두는 것과 반대로, 여기서는 좁은 채널 사이에 넓은 확장층을 두기 때문이다.
여기서 트래픽의 씨앗이 보인다. 가장 큰 텐서는 expand가 만든 넓은 텐서다. 그 텐서를 depthwise가 한 번 읽고 한 번 쓰며, project가 다시 한 번 읽는다. 그래서 그 큰 텐서는 트래픽에 세 번 등장한다. 이것이 03장에서 풀 메커니즘의 시작점이다.
2.3 대표 블록 두 개 — 위치만 다르면 성격이 뒤집힌다
이제 실제 블록 두 개를 한 바이트씩 분해한다. 둘 다 t=6에 stride 1이고 세 단계 구조가 같다. 다른 점은 위치뿐이다. 하나는 앞쪽 고해상도, 하나는 뒤쪽 저해상도에 있다. 결론을 미리 말하면, 앞 블록은 활성값이, 뒤 블록은 가중치가 트래픽을 지배한다. 같은 구조인데 정반대다.
블록 A — 앞쪽 고해상도 (입력 24채널 @ 56×56)
expand가 채널을 24개에서 144개로(24×6) 부풀린다. 해상도 56×56이 커서 텐서 한 장이 수백 KB에서 1 MB가 넘는다. 단계별로 01장의 셈을 그대로 적용한다.
| 단계 | 텐서 변화 | 파라미터 | 가중치 읽기 | 입력 읽기 | 출력 쓰기 | 활성값(읽기+쓰기) | 단계 합 | AI |
|---|---|---|---|---|---|---|---|---|
| expand 1×1 | 24@56² → 144@56² | 3,456 | 13.5 KB | 294.0 KB | 1,764 KB | 2,058 KB | 2,072 KB | 5.11 |
| depthwise 3×3 | 144@56² → 144@56² | 1,296 | 5.1 KB | 1,764 KB | 1,764 KB | 3,528 KB | 3,533 KB | 1.12 |
| project 1×1 | 144@56² → 24@56² | 3,456 | 13.5 KB | 1,764 KB | 294.0 KB | 2,058 KB | 2,072 KB | 5.11 |
| skip add | identity 읽기 + 합 쓰기 | — | — | — | — | 588 KB | 588 KB | — |
| 블록 합 | 8,208 | 32.1 KB | 8,232 KB | 8,264 KB | 3.04 |
읽는 법을 짚는다. expand 단계는 01.2절에서 손으로 센 바로 그 레이어다. depthwise는 채널 144개를 그대로 두고 3×3 커널을 채널마다 하나씩 적용한다. 파라미터는 144 × 3 × 3 = 1,296개뿐인데, 넓은 텐서(144@56², 1,764 KB)를 한 번 읽고 같은 크기를 한 번 쓴다. 그래서 활성값이 3,528 KB로 단계 중 가장 크다. project는 expand와 대칭이고, skip add는 입력을 한 번 읽고 합을 한 번 쓰므로 출력 텐서의 두 배인 588 KB다.
블록 전체를 보면 가중치는 32 KB로 0.4%, 활성값은 8,232 KB로 99.6%다. 파라미터가 8천 개뿐인데 트래픽의 99.6%가 중간 텐서를 쓰고 읽는 일이다. 특히 depthwise 단계의 연산강도는 1.12 MAC/byte다. 바이트 하나를 옮길 때 곱셈-누산을 겨우 한 번 남짓 한다. 가중치 재사용이 거의 없다는 뜻이다. 채널마다 커널이 하나뿐이라 그렇다(00.4절). 이 1.12라는 바닥값이 05장 roofline에서 다시 등장한다.
블록 B — 뒤쪽 저해상도 (입력 160채널 @ 7×7)
expand가 채널을 160개에서 960개로(160×6) 부풀린다. 채널 수는 블록 A보다 훨씬 크지만 해상도가 7×7로 작아, 텐서 한 장은 작다. 대신 1×1 가중치 행렬(160×960)이 커진다.
| 단계 | 텐서 변화 | 파라미터 | 가중치 읽기 | 입력 읽기 | 출력 쓰기 | 활성값(읽기+쓰기) | 단계 합 | AI |
|---|---|---|---|---|---|---|---|---|
| expand 1×1 | 160@7² → 960@7² | 153,600 | 600.0 KB | 30.6 KB | 183.8 KB | 214.4 KB | 814.4 KB | 9.03 |
| depthwise 3×3 | 960@7² → 960@7² | 8,640 | 33.8 KB | 183.8 KB | 183.8 KB | 367.5 KB | 401.3 KB | 1.03 |
| project 1×1 | 960@7² → 160@7² | 153,600 | 600.0 KB | 183.8 KB | 30.6 KB | 214.4 KB | 814.4 KB | 9.03 |
| skip add | identity 읽기 + 합 쓰기 | — | — | — | — | 61.3 KB | 61.3 KB | — |
| 블록 합 | 315,840 | 1,234 KB | 857.5 KB | 2,091 KB | 7.23 |
여기서는 가중치가 트래픽의 과반이다. 가중치 1,234 KB로 59%, 활성값 857.5 KB로 41%다. 파라미터가 315,840개로 블록 A의 38배인데, 트래픽 총합은 오히려 작다(2,091 KB 대 8,264 KB). 작은 해상도가 활성값을 눌렀고, 큰 1×1 가중치 행렬이 가중치 항을 키웠기 때문이다. 그래도 depthwise의 연산강도는 여전히 1.03으로 바닥이다. 위치가 어디든 depthwise는 재사용이 없다.
두 블록을 나란히
| 블록 | 위치 | 파라미터 | 가중치 트래픽 | 활성값 트래픽 | 합 | 지배 항 |
|---|---|---|---|---|---|---|
| A 앞쪽 | 24ch @ 56×56 | 8,208 | 32 KB (0.4%) | 8,232 KB (99.6%) | 8,264 KB | 활성값 |
| B 뒤쪽 | 160ch @ 7×7 | 315,840 | 1,234 KB (59%) | 857.5 KB (41%) | 2,091 KB | 가중치 |
같은 t=6, 같은 세 단계 구조인데 트래픽 성격이 정반대다. 해상도가 활성값을 키우고, 채널 폭이 가중치를 키운다. 이 한 표가 04장에서 다룰 "파라미터 수 ≠ 트래픽"의 첫 증거다. 파라미터가 38배 많은 블록이 트래픽은 4분의 1이다.
다음 그림은 이 두 블록을 단계별로 그린 것이다. 같은 세로 축을 써서 블록 A가 블록 B보다 얼마나 큰지 한눈에 보인다.
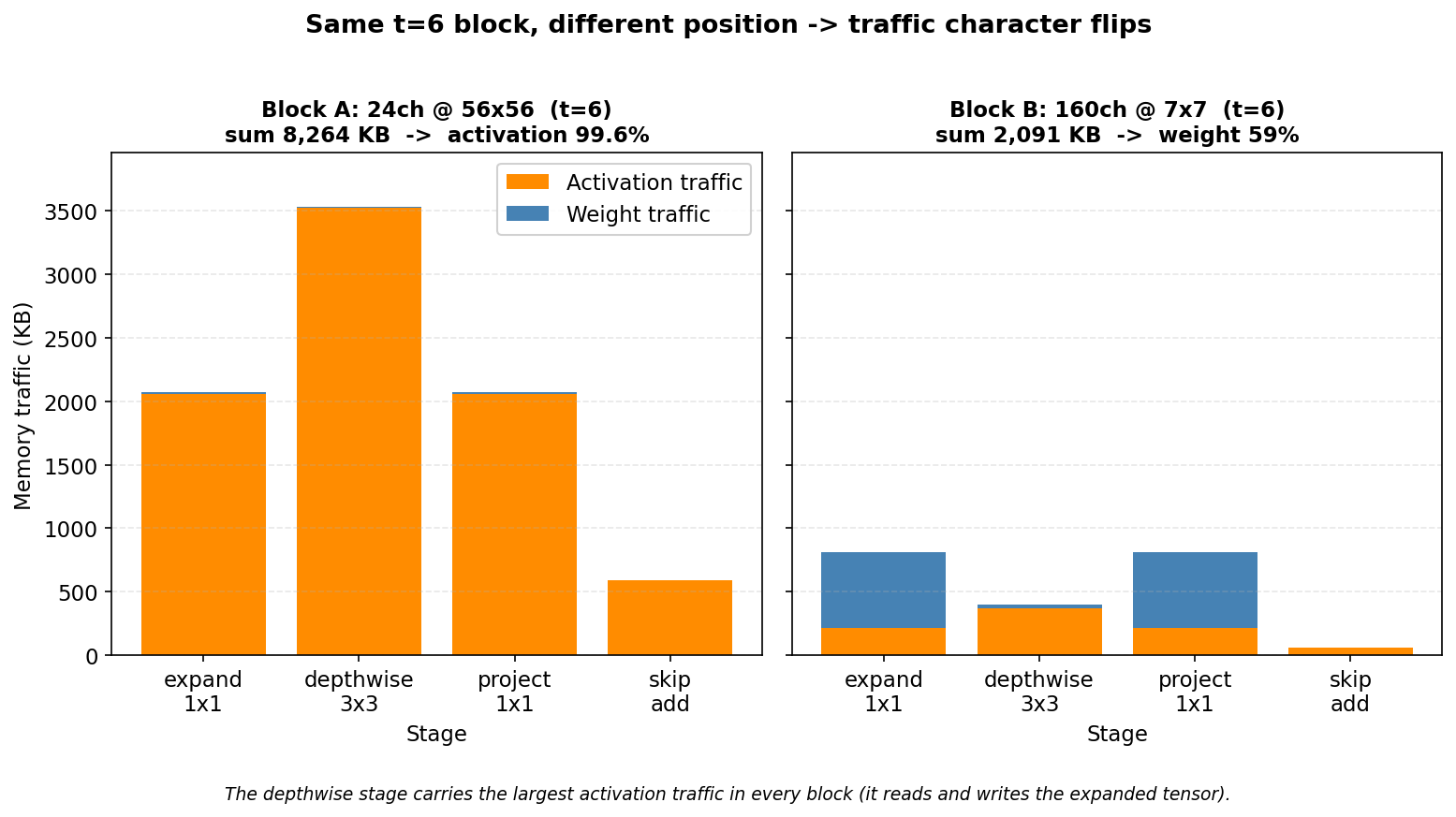
두 블록 모두에서 depthwise 단계(가운데)의 활성값이 단계 중 가장 크다. expand가 부풀린 넓은 텐서를 읽고 또 쓰기 때문이다.
이어지는 02a장에서 이 셈을 모든 레이어로 확장해, 전체 트래픽 66 MB가 어떻게 쌓이는지 본다.