· 파라미터 수와 메모리 트래픽은 왜 별개인가
세 번째 질문이다. 흔히 "파라미터가 적으면 가볍다"고 말한다. 모델 크기는 그 말이 맞다. 하지만 추론할 때 메모리를 오가는 양, 곧 트래픽은 다른 이야기다. 이 장은 파라미터 수와 트래픽이 별개의 양임을 worked example로 못 박는다. 먼저 둘이 무엇이 다른지 정의로 정리하고, 순위가 뒤집히는 사례를 보이고, batch를 키우며 둘의 운명이 갈리는 모습을 본다.
04.1 정적인 양과 동적인 양
파라미터 수와 트래픽이 헷갈리는 까닭은 둘이 겹치는 데가 있어서다. 트래픽의 한 항인 가중치 읽기가 파라미터 수에서 나온다. 그래서 "파라미터 = 트래픽"이라 착각하기 쉽다. 하지만 트래픽에는 활성값이라는 다른 항이 있고, 그 항이 보통 훨씬 크다.
- 파라미터 수는 모델이 가진 가중치의 개수다. 정적인 양이다. 모델을 정하면 끝이고, 입력 영상이나 batch와 무관하다. MobileNet-v2 1.0의 3.47 M개가 그 예다. 추론할 때 가중치는 한 번만 읽는다.
- 메모리 트래픽은 추론 한 번에 메모리를 오가는 바이트다. 동적인 양이다. 가중치 읽기에 더해, 활성값을 쓰고 읽는 트래픽이 들어간다. 활성값은 입력 해상도와 batch에 비례해 변한다.
트래픽을 구조식으로 적으면 둘의 관계가 분명해진다.
트래픽 = 가중치_읽기 (= 파라미터 수 × dtype, batch와 무관·1회)
+ 활성값_트래픽 (∝ batch × H × W × C)
파라미터 수는 트래픽의 첫 항 하나에만 영향을 준다. 그 항은 보통 작다(02장에서 전체의 20%였다). 트래픽의 대부분을 차지하는 활성값 항은 파라미터 수와 전혀 무관하다. 그래서 둘은 같은 방향으로 움직이지 않는다.
04.2 순위가 뒤집히는 사례
말로는 충분치 않으니 두 레이어를 나란히 둔다. 02장에서 분해한 두 블록에서 한 단계씩 꺼냈다. 하나는 블록 A의 depthwise(파라미터 적음), 하나는 블록 B의 project(파라미터 많음)다.
| 레이어 | 파라미터 | 가중치 트래픽 | 활성값 트래픽 | 지배 항 |
|---|---|---|---|---|
| 초기 depthwise (블록 A, 144ch @ 56×56) | 1,296 | 5.1 KB | 3,528 KB | 활성값 |
| 후기 project 1×1 (블록 B, 960→160 @ 7×7) | 153,600 | 600 KB | 214 KB | 가중치 |
읽는 법은 이렇다. 초기 depthwise는 가중치가 1,296개(5 KB)뿐인데 활성값을 3,528 KB나 옮긴다. 활성값이 가중치의 697배다. 파라미터 개수가 이 레이어의 트래픽을 전혀 대변하지 못한다. 반대로 후기 project는 파라미터가 153,600개로 118배 많지만, 트래픽 자체는 오히려 작고 그나마도 가중치가 정한다.
순위가 뒤집힌다는 점이 핵심이다. 파라미터가 적은 초기 depthwise가, 파라미터가 118배 많은 후기 project보다 트래픽이 더 크다. 얼마나 큰지 잴 때는 무엇을 기준으로 비교하는지 분명히 해야 한다. 활성값끼리 비교하면 depthwise가 project의 약 16배다(3,528 KB 대 214 KB). 레이어 전체 트래픽으로 비교하면 약 4배다(3,533 KB 대 814 KB). 둘 다 맞는 말이지만, 앞은 활성값 기준, 뒤는 전체 트래픽 기준이라 분모가 다르다. 어느 쪽이든 파라미터가 적은 쪽이 트래픽은 더 크다는 결론은 같다.
다음 그림은 모델의 여러 레이어를 파라미터 수(가로)와 트래픽(세로)으로 흩뿌린 것이다. 두 축이 로그 스케일이다.
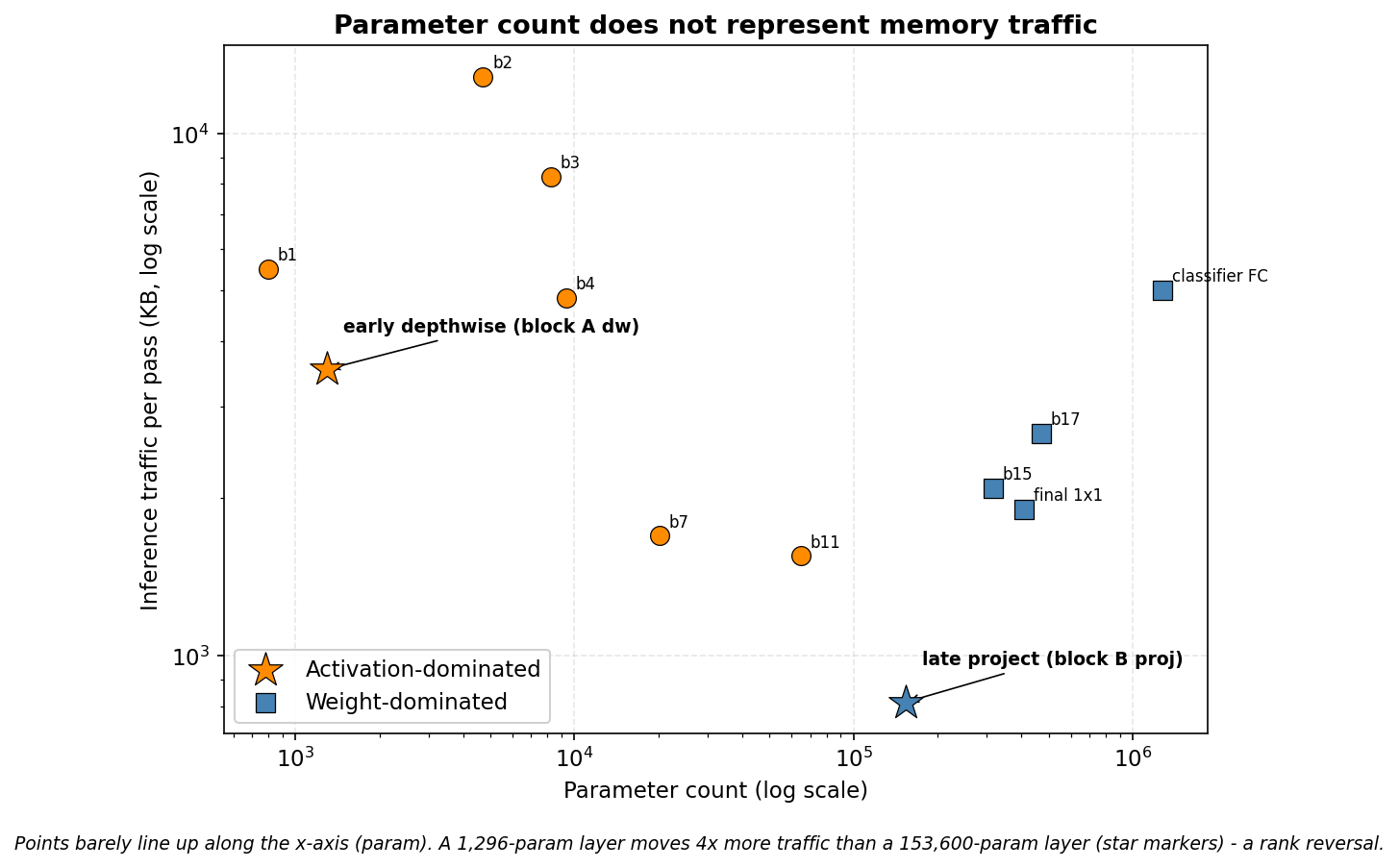
점들이 대각선으로 가지런히 늘어서 있다면 파라미터와 트래픽이 비례한다는 뜻일 것이다. 그러나 점들은 가로로 흩어져 있다. 파라미터가 작은 왼쪽에도 트래픽이 큰 점이 있고, 파라미터가 큰 오른쪽에도 트래픽이 작은 점이 있다. 주황 원(활성값 지배)과 파랑 사각(가중치 지배)이 섞여 있어, 같은 파라미터 수라도 어느 항이 트래픽을 정하는지가 레이어마다 다름을 보인다.
04.3 batch를 키우면 운명이 갈린다
파라미터와 트래픽이 별개임을 가장 깔끔하게 보이는 실험은 batch 키우기다. batch는 한 번에 처리하는 입력 영상의 수다. batch를 키워도 모델의 가중치는 한 벌 그대로다. batch 전체가 같은 가중치를 공유하므로 가중치는 한 번만 읽는다. 반면 활성값은 영상마다 따로 생기므로 batch에 정비례한다.
블록 A의 depthwise에서 batch를 키워 본다.
| batch N | 가중치 (불변) | 활성값 (N배) | 전체 트래픽 |
|---|---|---|---|
| 1 | 5.06 KB | 3,528 KB | 3,533 KB |
| 4 | 5.06 KB | 14,112 KB | 14,117 KB |
| 16 | 5.06 KB | 56,448 KB | 56,453 KB |
batch가 16이 되면 활성값은 55.1 MB로 16배 늘었는데, 가중치는 5.06 KB 그대로다. 파라미터 수와 가중치 트래픽은 한 글자도 안 변했는데 전체 트래픽은 16배가 됐다. 이보다 명확한 증거는 없다. 파라미터를 한 개도 안 늘리고 트래픽을 16배로 키운 것이다.
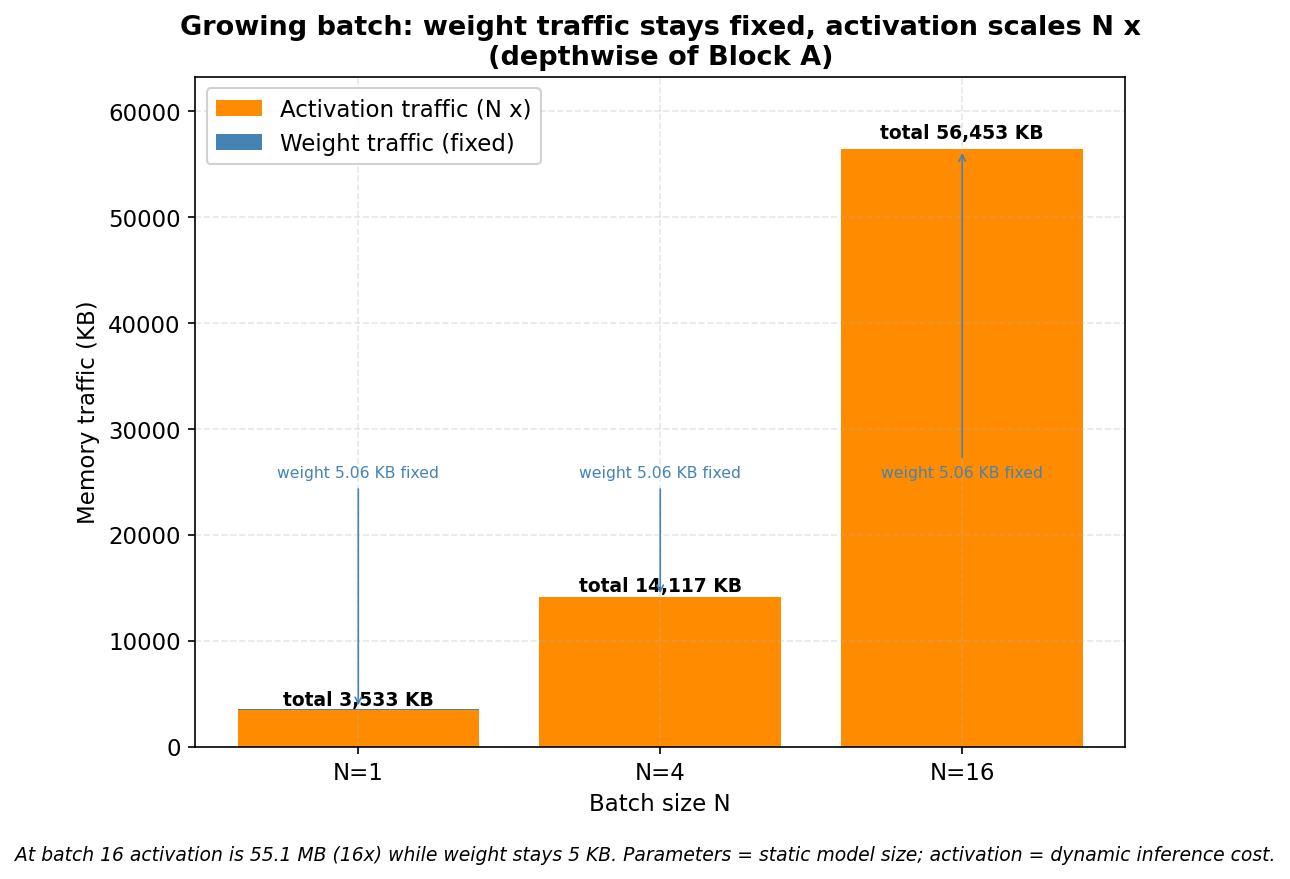
막대마다 파랑(가중치)이 거의 보이지 않을 만큼 작다. 주황(활성값)만 N에 따라 자란다.
입력 해상도를 키워도 결과는 같다. 입력을 224×224에서 448×448로 키우면 모든 활성값 텐서가 4배가 된다(높이와 너비가 각각 2배). 가중치 트래픽은 역시 불변이다. 활성값은 해상도의 제곱에 비례하기 때문이다.
04.4 정리
세 번째 질문의 답은 이렇다. 파라미터 수는 정적인 모델 크기이고, 트래픽은 동적인 추론 비용이다. 파라미터는 트래픽의 가중치 항 하나에만 영향을 주고, 그 항은 보통 작다. 트래픽의 대부분인 활성값은 해상도와 batch가 정하지 파라미터가 정하지 않는다. 그래서 파라미터가 적은 레이어가 트래픽은 더 클 수 있고(순위 역전), batch를 키우면 파라미터는 그대로인데 트래픽만 N배가 된다.
"파라미터가 적으니 메모리도 적다"는 말은 모델을 디스크에 저장할 때만 맞다. 추론할 때 칩이 옮기는 바이트를 따질 때는 틀린 말이다. 다음 장은 이 모든 트래픽이 칩 위에서 어떤 성능을 뜻하는지, roofline으로 마무리한다.