· inverted residual에서 왜 트래픽이 느나
02장에서 전체 트래픽의 80%가 활성값이고, 그 활성값이 bottleneck 블록 안에서 나온다는 것을 봤다. 이 장은 그 안쪽을 더 파고든다. 두 번째 질문이다. inverted residual 블록에서 트래픽이 왜 늘어나는가. 답은 한 문장으로 요약된다. expand 단계가 채널을 t배로 부풀리면, depthwise가 그 큰 텐서를 통째로 읽고 쓰므로 활성값 트래픽이 t에 비례해 커진다.
이 메커니즘을 말로 그치지 않고, 확장한 경로와 확장 안 한 경로를 수치로 나란히 놓고 확인한다.
03.1 확장한 텐서는 트래픽에 세 번 등장한다
먼저 단계 흐름을 다시 본다. 02장에서 봤듯이 가장 큰 텐서는 expand가 만든 넓은 텐서다.
expand가 만든 넓은 텐서를 따라가 보자. expand가 한 번 쓴다. depthwise가 그것을 입력으로 한 번 읽는다. depthwise가 결과를 한 번 쓴다. project가 그것을 입력으로 한 번 읽는다. 곧 넓은 텐서는 쓰기 한 번, 읽기 한 번, 다시 쓰기 한 번, 읽기 한 번으로 트래픽에 거듭 나타난다. 이 텐서가 t배 넓어지면, 이 모든 등장이 함께 t배가 된다. 트래픽이 느는 까닭의 핵심이 여기 있다.
여기서 depthwise의 성질이 결정적이다. depthwise 합성곱은 채널마다 독립된 커널을 하나씩 적용한다. 채널 간에 섞지 않는다. 그래서 입력 채널 수를 줄이지 못한다. expand가 채널을 144개로 늘려 놓는다고 하자. depthwise는 그 채널 수를 그대로 받아 그대로 내보낸다. 채널을 좁히는 일은 그 뒤 project가 한다. 결국 넓은 텐서는 depthwise를 통과하는 내내 넓은 채로 있고, 읽기와 쓰기가 동시에 t배가 된다.
03.2 확장한 경로 대 안 한 경로 — 직접 대조
이제 수치로 확인한다. 02장의 블록 A 모양을 그대로 쓴다. 입력 24채널 @ 56×56, stride 1이다. 두 경로를 비교한다. 하나는 실제 MobileNet-v2처럼 t=6으로 확장하는 경로다. 다른 하나는 확장을 아예 하지 않는 가상의 경로(t=1, 채널을 24개 그대로)다.
먼저 depthwise가 다루는 텐서 크기만 본다. 이것이 확장의 가장 직접적인 효과다.
| 경로 | depthwise 입력 텐서 | 크기 (FP32) |
|---|---|---|
| 실제 t=6 (확장함) | 144 @ 56×56 | 1,764 KB |
| 가상 t=1 (확장 안 함) | 24 @ 56×56 | 294 KB |
| 비율 | 6.0× (정확히 t) |
depthwise가 읽고 쓰는 텐서가 정확히 6배, 곧 t배 커진다. depthwise는 채널을 못 줄이므로, expand가 키운 채널 수가 고스란히 텐서 크기에 반영된다.
블록 전체 활성값 트래픽으로 넓혀 본다.
| 경로 | expand 활성값 | depthwise 활성값 | project 활성값 | skip | 블록 활성값 합 |
|---|---|---|---|---|---|
| 실제 t=6 | 2,058 KB | 3,528 KB | 2,058 KB | 588 KB | 8,232 KB |
| 가상 t=1 | — (확장 없음) | 588 KB | 588 KB | 588 KB | 1,764 KB |
| 비율 | 6.00× | 3.50× | 1× | 4.67× |
확장 하나가 블록 전체 활성값 트래픽을 4.67배로 키운다. 단계별로 보면, 넓은 텐서를 직접 다루는 depthwise 단계가 정확히 6.00배, expand·project 단계가 3.50배다. skip add만 비율이 1배다. skip은 출력 채널(C_out) 기준이라 t와 무관하기 때문이다. 그 고정된 588 KB가 비율을 살짝 희석해, 블록 전체로는 6배가 아니라 4.67배가 된다.
여기서 linear bottleneck을 한 마디 짚는다. project 뒤에 활성함수를 붙이지 않는다는 그 설계는 트래픽 회계에 영향을 주지 않는다. ReLU6 같은 활성함수는 자기 자리에서 값을 덮어쓰는 in-place 연산이라 별도 텐서를 만들지 않기 때문이다. project의 출력 텐서는 활성함수가 있든 없든 어차피 한 번 쓰고 다음 단계가 한 번 읽는다.
03.3 t를 키우면 트래픽도 따라 큰다
확장계수 t만 바꿔 가며 블록 활성값 트래픽이 어떻게 변하는지 본다. 블록 A 모양은 그대로 두고 t만 1에서 10까지 훑는다.
| t | 확장 채널 | expand | depthwise | project | skip | 블록 활성값 합 (KB) |
|---|---|---|---|---|---|---|
| 1 | 24 | 0 | 588 | 588 | 588 | 1,764 |
| 2 | 48 | 882 | 1,176 | 882 | 588 | 3,528 |
| 3 | 72 | 1,176 | 1,764 | 1,176 | 588 | 4,704 |
| 4 | 96 | 1,470 | 2,352 | 1,470 | 588 | 5,880 |
| 6 | 144 | 2,058 | 3,528 | 2,058 | 588 | 8,232 |
| 8 | 192 | 2,646 | 4,704 | 2,646 | 588 | 10,584 |
| 10 | 240 | 3,234 | 5,880 | 3,234 | 588 | 12,936 |
트래픽이 t를 따라 거의 선형으로 는다. 완전한 비례가 아닌 까닭은 skip의 고정된 588 KB 절편 때문이다. 그 절편을 빼고 보면 확장 텐서를 다루는 항들은 t에 정확히 비례한다. MobileNet-v2가 쓰는 t=6은 t=1 대비 4.67배다.
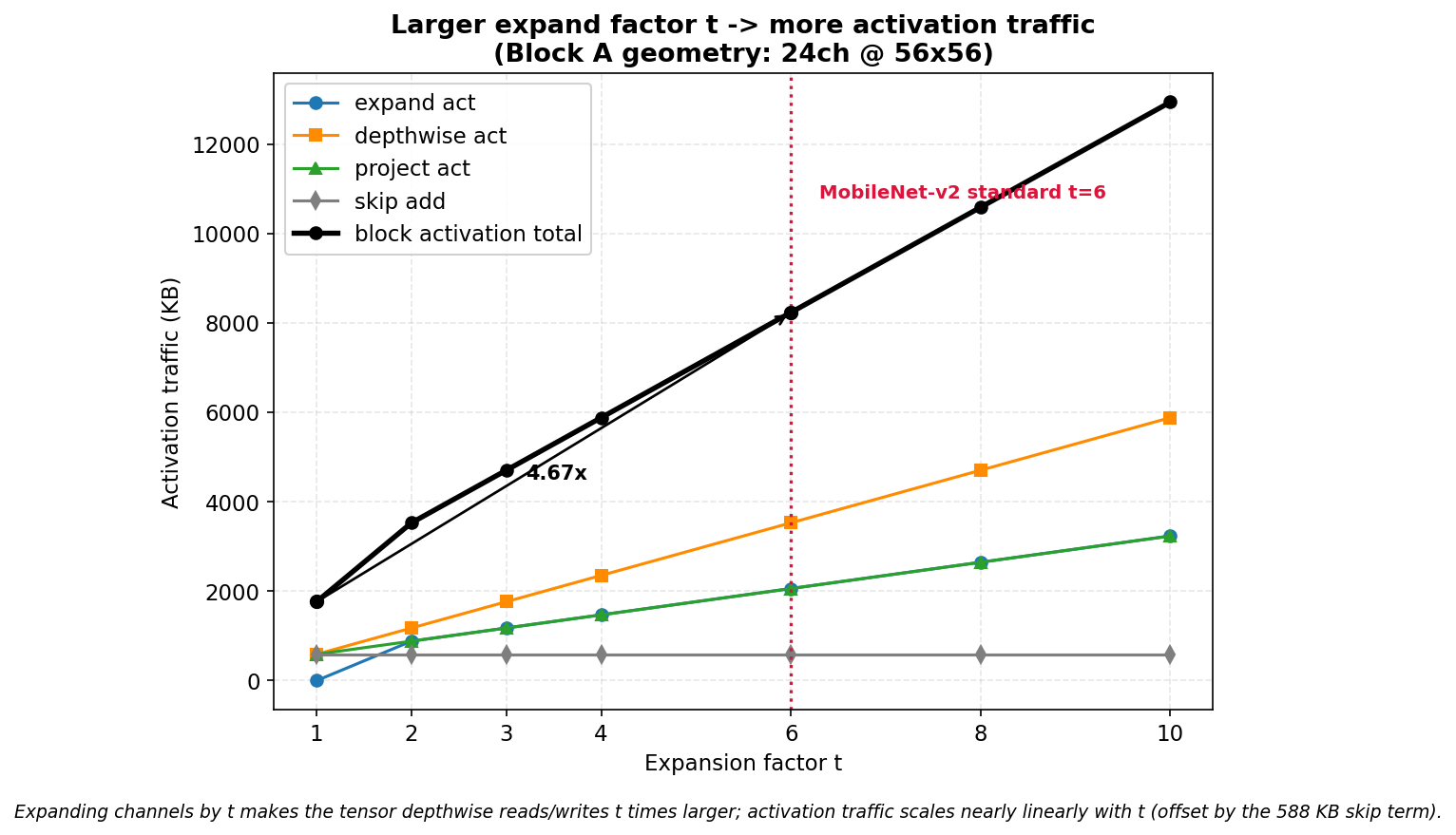
세로 점선이 표준 t=6 지점이다. 단계별 선 네 개가 모두 우상향하는데, depthwise 선이 가장 가파르다. 넓은 텐서를 읽고 또 쓰기 때문이다.
03.4 정리
두 번째 질문의 답은 이렇다. inverted residual에서 트래픽이 느는 까닭은 expand가 채널을 t배로 부풀리고, 채널을 못 줄이는 depthwise가 그 큰 텐서를 읽고 쓰기 때문이다. 활성값 트래픽이 t에 거의 비례해 늘어, t=6에서는 확장 없는 경우의 4.67배가 된다. 확장이 트래픽 증가의 원인이고, 그 양은 t로 조절된다.
확장은 정확도를 위한 설계다. 넓은 채널에서 비선형 변환을 거쳐야 표현력이 좋아지기 때문이다. 그 대가가 메모리 트래픽이다. 이 맞바꿈을 이해하면, 왜 모바일 모델 설계가 늘 트래픽과 씨름하는지 보인다.