02a · 전체 네트워크 트래픽 — 66 MB가 쌓이는 과정
02장에서 대표 블록 두 개를 분해했다. 이제 같은 셈을 MobileNet-v2의 모든 부분에 적용한다. bottleneck 블록 17개에 앞쪽 stem 합성곱, 마지막 1×1 합성곱, 분류기 전결합층을 더한 전체다. 한 블록씩 트래픽을 세어 늘어놓으면, 활성값과 가중치 중 누가 어디서 트래픽을 지배하는지가 모델 깊이를 따라 드러난다.
02a.1 블록별 트래픽 — 깊이를 따라 역전된다
다음은 모든 블록과 레이어의 가중치·활성값 트래픽이다(FP32, batch 1). 같은 모양을 반복하는 블록은 한 줄로 묶었다.
| 블록 | 입력 해상도 | 채널 (입력→출력) | t | 가중치 | 활성값 | 합 |
|---|---|---|---|---|---|---|
| stem 3×3 s2 | 224 | 3→32 | — | 3.4 KB | 2,156 KB | 2,159 KB |
| b1 | 112 | 32→16 | 1 | 3.1 KB | 5,488 KB | 5,491 KB |
| b2 | 112 | 16→24 | 6 | 18.4 KB | 12,838 KB | 12,856 KB |
| b3 | 56 | 24→24 | 6 | 32.1 KB | 8,232 KB | 8,264 KB |
| b4 | 56 | 24→32 | 6 | 36.6 KB | 4,802 KB | 4,839 KB |
| b5–b6 | 28 | 32→32 | 6 | 54.8 KB | 2,744 KB | 2,799 KB |
| b7 | 28 | 32→64 | 6 | 78.8 KB | 1,617 KB | 1,696 KB |
| b8–b10 | 14 | 64→64 | 6 | 205.5 KB | 1,372 KB | 1,578 KB |
| b11 | 14 | 64→96 | 6 | 253.5 KB | 1,298 KB | 1,552 KB |
| b12–b13 | 14 | 96→96 | 6 | 452.2 KB | 2,058 KB | 2,510 KB |
| b14 | 14 | 96→160 | 6 | 596.2 KB | 1,207 KB | 1,803 KB |
| b15–b16 | 7 | 160→160 | 6 | 1,234 KB | 857.5 KB | 2,091 KB |
| b17 | 7 | 160→320 | 6 | 1,834 KB | 826.9 KB | 2,661 KB |
| final 1×1 | 7 | 320→1280 | — | 1,600 KB | 306.2 KB | 1,906 KB |
| classifier FC | — | 1280→1000 | — | 5,000 KB | 8.9 KB | 5,009 KB |
(b3은 02장의 블록 A, b15는 블록 B와 같은 모양이다. 표의 KB 단위 합이 그 장의 8,264 KB·2,091 KB와 맞는지 확인해 보면 셈이 일관됨을 알 수 있다.)
표를 위에서 아래로 읽으면 한 가지 흐름이 보인다. 위쪽 고해상도 블록에서는 활성값이 크고, 아래쪽 저해상도 블록으로 갈수록 가중치가 점점 커진다. b2에서 활성값이 12.8 MB로 가장 크고, classifier FC에서는 가중치가 5 MB인데 활성값은 9 KB뿐이다. 분류기는 극단적인 가중치 지배다. 파라미터 128만 개를 읽는데 활성값은 거의 없다. 이런 레이어가 가중치 지배 memory-bound 분류기(classifier head)의 전형이다.
다음 그림은 이 표를 누적 막대로 그린 것이다. 막대 하나가 한 블록이고, 아래가 가중치, 위가 활성값이다.
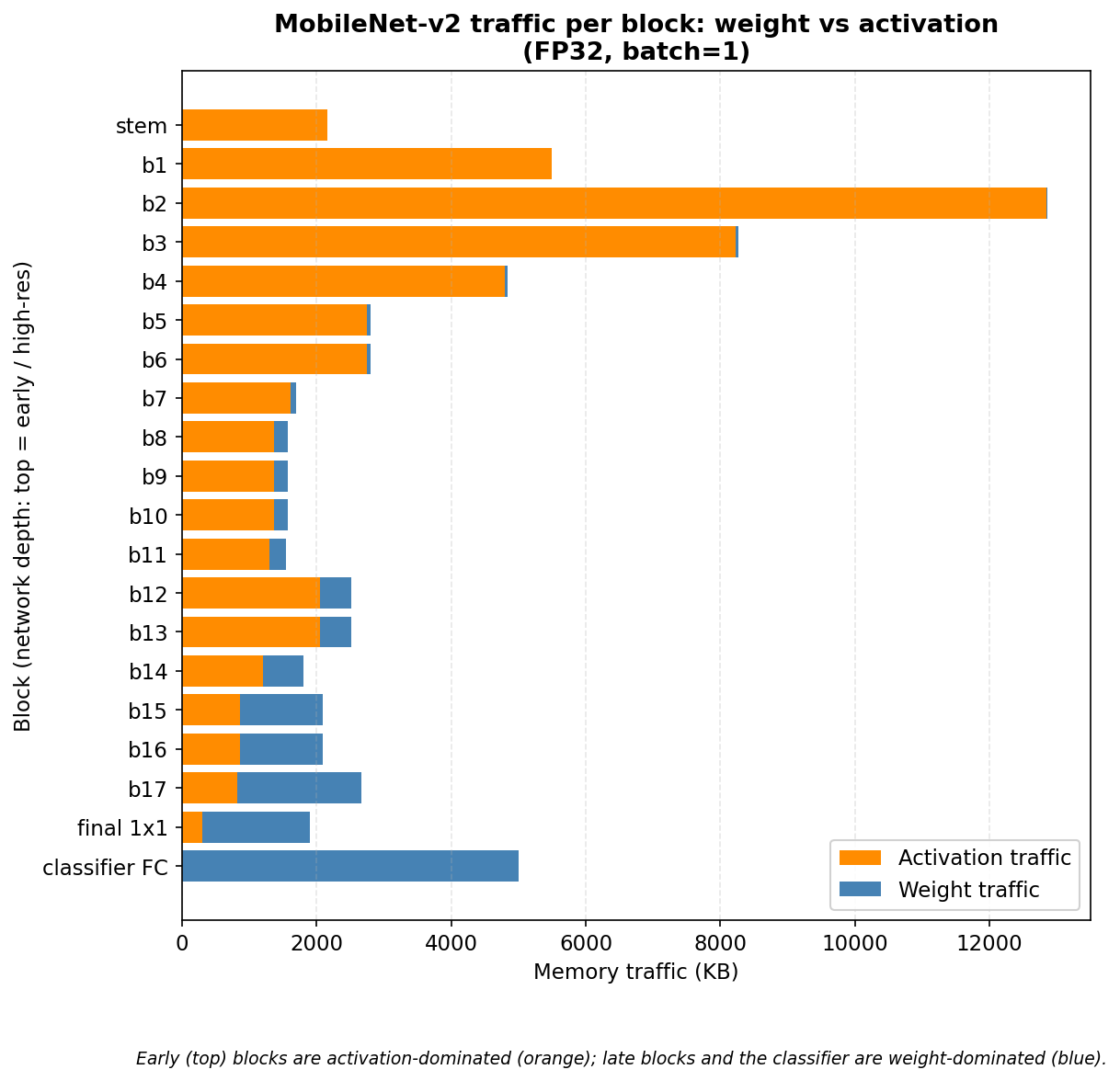
왼쪽 초기 블록들은 주황(활성값)이 막대를 거의 다 채우고, 오른쪽으로 갈수록 파랑(가중치)이 자란다. 트래픽의 두 항이 네트워크 깊이를 따라 역전된다.
02a.2 해상도 밴드로 묶어 보기 — 활성값의 발원지
블록을 해상도별로 묶으면 활성값이 어디서 나오는지가 더 또렷해진다. 같은 해상도에서 도는 블록들의 가중치와 활성값을 각각 더한 표다.
| 해상도 밴드 | 가중치 합 | 활성값 합 | 활성값 ÷ 가중치 |
|---|---|---|---|
| 112×112 | 21.5 KB | 18,326 KB | 852× |
| 56×56 | 68.6 KB | 13,034 KB | 190× |
| 28×28 | 188.2 KB | 7,105 KB | 38× |
| 14×14 | 2,371 KB | 10,737 KB | 4.5× |
| 7×7 | 4,301 KB | 2,542 KB | 0.59× |
해상도가 절반씩 줄수록(픽셀 수는 4분의 1씩) 활성값은 줄고 가중치는 는다. 112×112 밴드에서는 활성값이 가중치의 852배다. 7×7 밴드에서는 0.59배로, 처음으로 가중치가 더 크다. 활성값 비가 852배에서 0.59배로 뒤집히는 이 흐름이 곧 트래픽 성격의 역전이다.
가장 중요한 수치 하나. 초기 두 밴드(112×112와 56×56)만으로 활성값이 30.62 MB다. 이것은 bottleneck 블록들의 활성값 합 기준으로 약 60%에 해당한다. 다시 말해, 활성값 트래픽의 발원지는 모델 앞쪽의 고해상도 레이어다. 그런데 그 앞쪽 레이어들은 가중치가 거의 없다. 112×112 밴드의 가중치는 21.5 KB뿐이다. 파라미터가 가장 적은 곳에서 트래픽이 가장 크다.
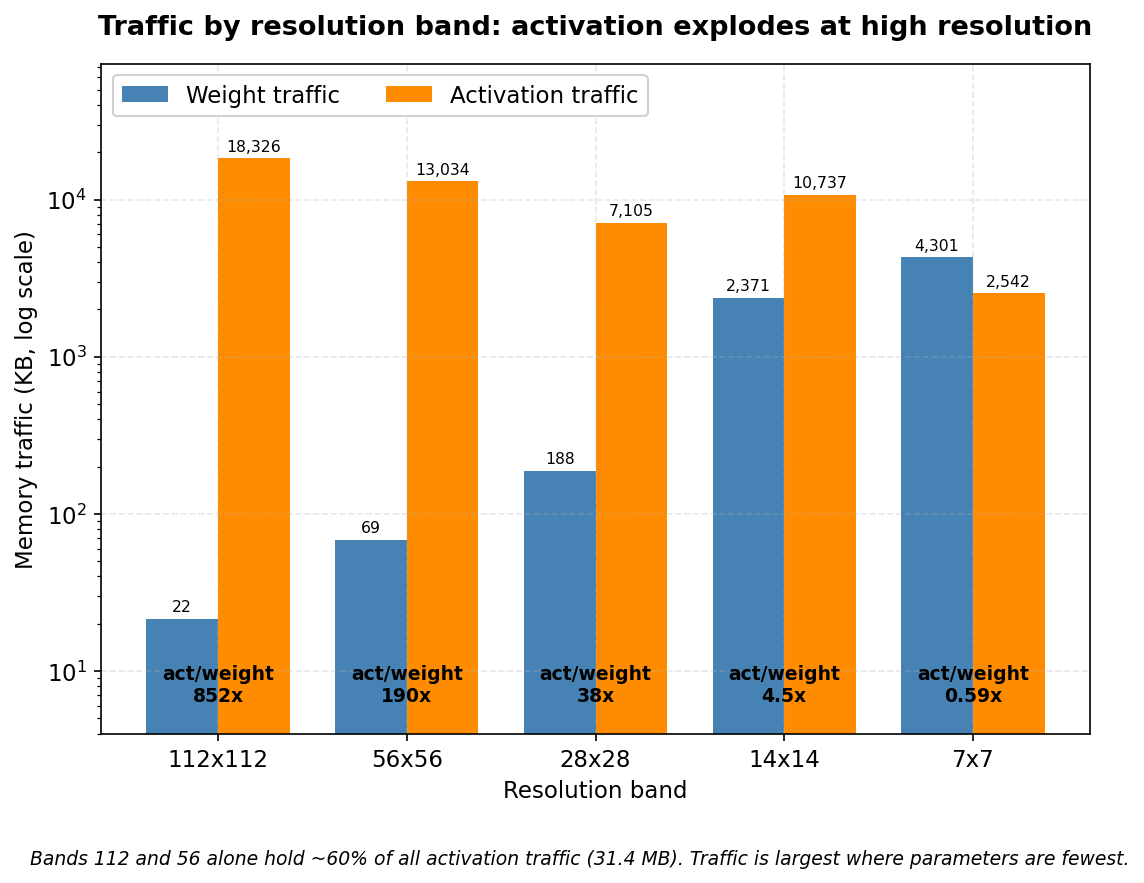
세로 축이 로그 스케일이라 값의 큰 차이가 한 화면에 담긴다. 각 밴드 위의 비율 숫자가 활성값이 가중치의 몇 배인지 보여 준다.
02a.3 전체 합계 — 가벼운 모델의 무거운 트래픽
모든 항을 더하면 전체 트래픽이 나온다.
| 항목 | FP32 (4 byte) | 비고 |
|---|---|---|
| 총 파라미터 | 3.47 M | 문헌의 ~3.4 M과 일치 |
| 총 MAC | 301 M | 문헌의 ~300 M과 일치 |
| 가중치 트래픽 | 13.24 MB | 파라미터 수 × 4 byte |
| 활성값 트래픽 | 52.94 MB | 중간 텐서 읽기+쓰기 |
| 전체 트래픽 | 66.18 MB | |
| 가중치 : 활성값 | 20% : 80% | |
| 전체 연산강도 | 4.3 MAC/byte |
손으로 센 총 파라미터 3.47 M개와 총 MAC 301 M번이 공개 문헌의 약 3.4 M, 약 300 M과 맞는다. 셈이 옳다는 증거다.
핵심은 세 수치다. 가중치를 다 합쳐도 13.24 MB인데, 활성값은 52.94 MB로 그 4배다. 전체 66.18 MB 중 활성값이 80%를 차지한다. "파라미터 3.4 M개에 곱셈 300 M번인 가벼운 모델"이 메모리에서는 한 번 추론에 66 MB를 옮긴다.
이 66 MB가 왜 문제인지 감을 잡으려면 대역폭과 비교해 보면 된다. 메모리 대역폭이 25.6 GB/s인 칩이라면, 66 MB를 옮기는 데에만 약 2.6 ms가 든다(66 MB ÷ 25.6 GB/s). 이것은 연산 시간이 아니라 데이터를 옮기는 시간만이다. 연산기가 아무리 빨라도 이 시간은 줄지 않는다. 연산강도 4.3 MAC/byte가 칩 ridge보다 한참 낮으니 그렇다. 이것이 memory-bound의 정량적 뿌리다. 자세한 판정은 05장 roofline에서 한다.
여기까지가 첫 질문의 답이다. 메모리 트래픽은 가중치 읽기와 활성값 읽기·쓰기의 합이고, MobileNet-v2에서는 활성값이 80%를 차지하며, 그 활성값은 앞쪽 고해상도 레이어에서 나온다. 다음 장은 두 번째 질문으로 넘어간다. inverted residual 블록에서 트래픽이 왜 늘어나는가.