다중분류 ROC: OvR로 쪼개고, macro·micro로 합치기
Contents
학습목표 — 이 장을 마치면 다음을 할 수 있다.
- OvR(one-vs-rest) 방식으로 K-클래스 문제를 K개의 이진 ROC로 분해한다.
- macro 평균(클래스별 AUC 단순평균)과 micro 평균(전 결정 풀링)의 차이를 설명한다.
- 클래스 불균형이 macro와 micro에 어떻게 다르게 영향을 미치는지 비교한다.
ROC는 양·음 두 칸짜리였다
지금까지 ROC와 AUC는 모두 이진 분류 — 양성과 음성, 단 두 클래스 — 위에서만 정의됐다. TPR도 FPR도 "양성"과 "음성"이라는 두 진영이 있어야 계산할 수 있었다.
그런데 현실의 분류 문제는 종종 셋 이상이다. 손글씨 숫자는 0~9까지 열 종류, 동물 사진은 개·고양이·새, 뉴스 기사는 정치·경제·스포츠. 이렇게 클래스가 K개(K ≥ 3) 인 문제를 다중분류(multiclass) 라 부른다. ROC 평면은 양·음 두 축으로 만들어졌는데, 클래스가 셋이면 "양성"이 무엇이고 "음성"이 무엇인지부터 모호해진다.
그래서 우리는 다중분류를 여러 개의 이진 문제로 쪼갠 다음, 각각에서 이미 아는 ROC를 그리고, 마지막에 다시 하나로 합친다. 이 "쪼개고 → 합치기" 전략이 이 챕터의 전부다.
OvR: 한 클래스를 양성, 나머지 전부를 음성으로
쪼개는 방법은 의외로 단순하다. one-vs-rest(OvR, 하나 대 나머지) 라고 부른다.
클래스가 A, B, C 셋이라 하자. OvR은 이렇게 한다.
- 클래스 A 관점: "A = 양성, B와 C = 전부 음성"으로 보고 이진 ROC를 한 장 그린다.
- 클래스 B 관점: "B = 양성, A와 C = 전부 음성"으로 보고 또 한 장.
- 클래스 C 관점: "C = 양성, A와 B = 전부 음성"으로 보고 또 한 장.
즉 클래스마다 그 클래스만 양성으로 놓고 나머지를 한 덩어리 음성으로 뭉쳐, 우리가 이미 아는 이진 ROC를 그리는 것이다. K개 클래스면 K개의 ROC 곡선과 K개의 AUC가 나온다.
비유: 반에 학생이 30명이고 키 순위를 매긴다고 하자. "철수 대 나머지 전부", "영희 대 나머지 전부" 식으로 한 사람씩 주인공으로 세우고 나머지를 배경으로 돌리면, 각 주인공에 대한 별도의 이진 비교가 만들어진다. OvR이 클래스에 하는 일이 바로 이것이다.
각 OvR 곡선의 AUC는 "이 모델이 해당 클래스를 나머지로부터 얼마나 잘 분리하는가"를 말해 준다. 어떤 클래스는 잘 구분되고(AUC 높음), 어떤 클래스는 다른 클래스와 헷갈려(AUC 낮음) 곡선이 처질 수 있다.
합치기: macro 평균과 micro 평균
K개의 AUC를 손에 쥐었다. 그런데 보고서에는 "이 모델의 ROC 성능은 한마디로 얼마인가?"라는 하나의 숫자가 필요할 때가 많다. K개를 하나로 합치는 방법이 두 가지이고, 둘은 서로 다른 질문에 답한다.
macro 평균 — 클래스를 평등하게
macro 평균은 K개의 OvR AUC를 그냥 단순 산술평균한다.
핵심은 클래스 크기를 무시한다는 점이다. 표본이 1000개인 큰 클래스든 30개인 작은 클래스든, 평균에 들어갈 때 똑같이 한 표씩 행사한다. 그래서 macro 평균은 작은 클래스가 잘 분류되는지에도 동등한 비중을 둔다.
micro 평균 — 결정을 평등하게
micro 평균은 접근이 다르다. K개의 곡선을 따로 만들어 평균 내는 대신, 모든 클래스의 (점수, 정답) 결정을 하나의 거대한 풀(pool)로 합쳐 단 하나의 ROC 곡선을 그린다. OvR로 만든 모든 이진 판단 — "이 표본은 A인가 아닌가", "저 표본은 B인가 아닌가" … — 을 전부 한 통에 쏟아붓고, 그 통 전체에서 ROC를 한 번 그리는 것이다.
이렇게 하면 표본이 많은 큰 클래스의 결정이 풀에 더 많이 들어가므로, micro 평균은 자연히 빈도 가중(frequency-weighted) 이 된다. 즉 큰 클래스의 성능이 최종 숫자에 더 크게 반영된다.
정리하면: macro는 "클래스마다 한 표"(평등 가중), micro는 "표본마다 한 표"(빈도 가중) 다. 작은 클래스를 큰 클래스만큼 중요하게 여기고 싶으면 macro, 전체 사례 단위의 평균 성능을 알고 싶으면 micro.
불균형이 둘을 갈라놓는다
macro와 micro의 차이는 클래스가 불균형할 때 비로소 또렷해진다.
작은 클래스 하나가 유독 분류가 어려워 AUC가 낮다고 하자.
- macro 평균에서는 이 작은 클래스도 한 표를 온전히 행사하므로, 낮은 AUC가 평균을 눈에 띄게 끌어내린다. macro는 "약한 클래스의 비명"을 그대로 듣는다.
- micro 평균에서는 이 작은 클래스의 결정 수가 풀에서 차지하는 비중이 작으므로, 그 약점이 큰 클래스들의 좋은 성능에 묻혀 거의 드러나지 않는다. micro는 다수의 목소리를 듣는다.
반대로 클래스가 균형 잡혀 있으면 macro와 micro는 비슷한 값으로 수렴한다 — 모든 클래스가 표본 수도, 표 수도 엇비슷하니 두 가중 방식이 사실상 같아지기 때문이다.
그래서 다중분류 평가에서는 둘을 함께 보고, 둘이 벌어지면 그 차이 자체를 신호로 읽는다. macro가 micro보다 뚜렷이 낮다면, "전체적으로는 괜찮은데 어떤 소수 클래스를 잘 못 맞히고 있다"는 경고다.
아래 그림은 3-클래스 문제에서 클래스별 OvR ROC 세 곡선과, 그것을 합친 macro·micro 평균 곡선을 한 장에 담은 것이다.
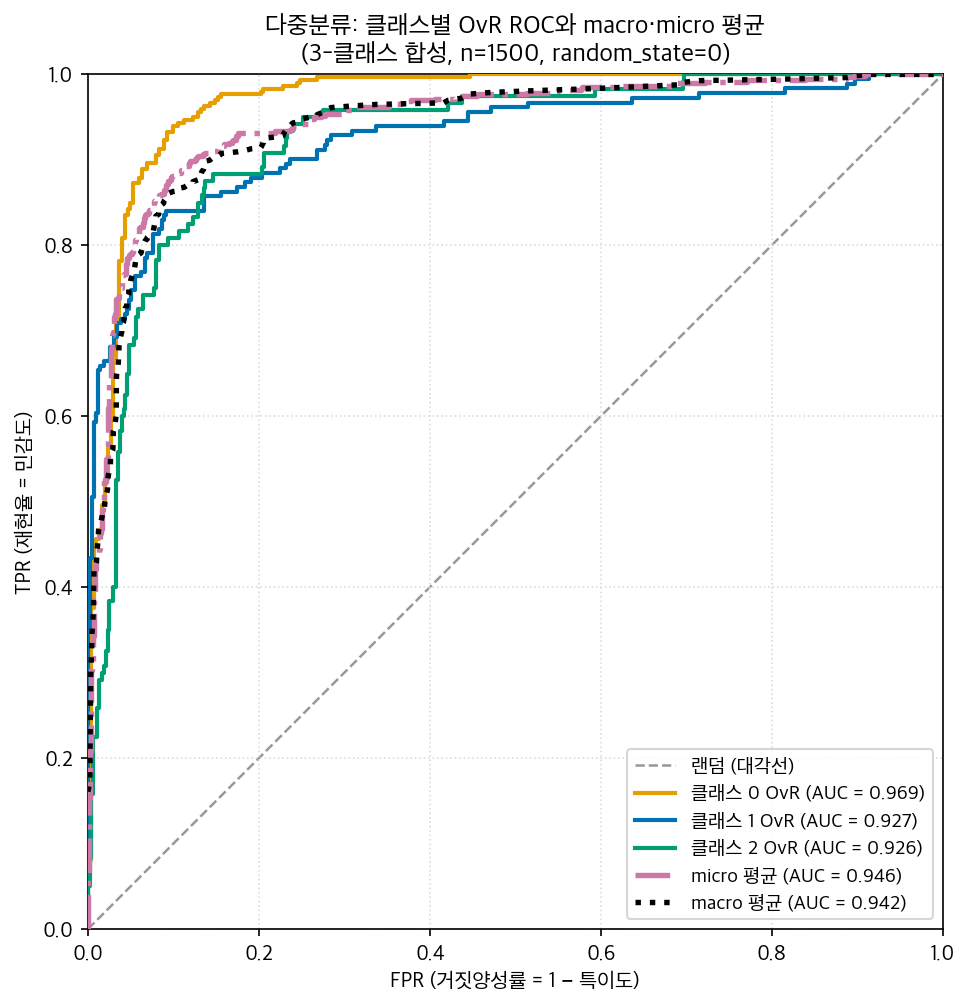
위 그림에서 클래스마다 곡선의 부풀어 오른 정도(분리력)가 다르고, macro·micro 두 평균선이 그 사이를 지나가는 것을 볼 수 있다.
정리: 쪼개고, 합치되, 어떻게 합쳤는지 기억하라
다중분류 ROC는 OvR로 K개의 이진 ROC로 쪼개고, 그 K개의 AUC를 macro(클래스 평등 평균) 또는 micro(결정 풀링, 빈도 가중) 로 합쳐 하나의 숫자로 요약한다. 어느 평균을 골랐는지가 곧 "무엇을 중요하게 봤는지"를 뜻하므로, 보고할 때는 평균 방식을 반드시 밝혀야 한다.
아래 그림은 K-클래스 문제가 OvR로 분해되고, 다시 macro·micro 두 갈래로 합쳐지는 전체 흐름이다.
이제 우리는 임계값 선택, 불균형, 다중분류까지 ROC·AUC의 실전 도구를 모두 손에 넣었다. 다음 챕터 08 — 자주 하는 오해와 주의점에서는 이 도구들을 둘러싼 흔한 오해와 함정을 한자리에 모아 비판적으로 점검한다.