토대: 점수·임계값·예측과 혼동행렬
목차
- 0-1. 이진 분류란 무엇인가 — "둘 중 하나로 가르는 일"
- 0-2. 점수와 임계값과 예측 — ROC 전체의 씨앗
- 분류기는 사실 "예/아니오"를 바로 말하지 않는다
- 점수는 "순위"이지 아직 "결정"이 아니다
- 왜 이 구분이 ROC의 씨앗인가
- 0-3. 혼동행렬 — 예측을 채점하는 2×2 표
- 채점에는 두 가지 정보가 필요하다
- 네 칸의 이름과 그 작명 규칙
- 합으로 나오는 두 가지 전체 수: P와 N
- 0-4. 네 칸을 몸으로 느끼기 — 세 가지 정확한 비유
- 비유 1 — 질병 검사 (양성 = 병이 있음)
- 비유 2 — 스팸 필터 (양성 = 스팸)
- 비유 3 — 화재경보 (양성 = 실제 화재)
- 0-5. 네 칸에서 짜내는 네 가지 비율 — 정밀도·재현율·특이도·FPR
- (1) 재현율(Recall) = TPR = 민감도(Sensitivity) — "놓치지 않는 능력"
- (2) 특이도(Specificity) — "건강한 사람을 잘 거르는 능력"
- (3) FPR(False Positive Rate) = 1 − 특이도 — "거짓 경보를 내는 비율"
- (4) 정밀도(Precision) — "양성이라 외쳤을 때 그게 맞을 확률"
- 흔한 오개념 — "정밀도와 재현율은 결국 같은 거 아닌가?"
- 0-6. 손으로 직접 계산해 보기
- 0-7. 이 장에서 챙긴 것, 그리고 다음 장으로
학습목표 — 이 장을 마치면 다음을 할 수 있다.
- 이진 분류에서 점수(score)·임계값(threshold)·예측(prediction)의 차이를 자기 말로 설명한다.
- 2×2 혼동행렬의 네 칸 TP·FP·FN·TN을 구분하고, 각 칸을 일상 비유(질병 검사·스팸 필터·화재경보)와 연결한다.
- 주어진 혼동행렬에서 정밀도·재현율(=TPR)·특이도·FPR을 직접 계산한다.
- TPR = recall = sensitivity, FPR = 1 − specificity 임을 진술한다.
이 책 전체는 ROC 곡선과 AUC라는 단 두 개의 도구를 깊이 이해하는 것이 목표다. 그런데 ROC와 AUC는 갑자기 하늘에서 떨어진 개념이 아니다. 그 둘은 혼동행렬이라는 더 작고 단단한 토대 위에 세워진 건물이다. 토대가 흔들리면 그 위의 모든 것이 흔들린다. 그래서 이 첫 장은 욕심을 부리지 않는다. ROC라는 단어는 거의 꺼내지도 않을 것이다. 대신 그 모든 것의 재료가 되는 점수·임계값·예측, 그리고 혼동행렬의 네 칸을 — 통계나 코딩을 한 번도 본 적 없는 사람이 막히지 않을 만큼 — 천천히 풀어 쓴다. 이 장에서 정의한 용어들은 뒤의 모든 장에서 다시 정의하지 않고 이름만 불러 쓸 것이다. 그러니 여기서만큼은 서두르지 말자.
0-1. 이진 분류란 무엇인가 — "둘 중 하나로 가르는 일"
세상에는 "예/아니오"로 답해야 하는 질문이 아주 많다. 이 이메일은 스팸인가, 아닌가? 이 환자는 병이 있는가, 없는가? 이 거래는 사기인가, 아닌가? 이렇게 모든 사례를 두 부류 중 하나로 가르는 일을 이진 분류(binary classification)라고 부른다. "이진(binary)"은 그냥 "둘"이라는 뜻이다. 둘 중 우리가 관심을 갖고 찾으려는 쪽을 양성(positive), 나머지 쪽을 음성(negative)이라고 부른다.
여기서 첫 번째로 마음에 새길 것이 있다. "양성"은 "좋은 것"이라는 뜻이 절대 아니다. 일상어의 "긍정적"과 헷갈리기 쉽지만, 분류에서 양성은 그저 "우리가 검출하려는 표적"일 뿐이다.
- 질병 검사에서 양성 = 병이 있음 (좋은 일이 아니다)
- 스팸 필터에서 양성 = 스팸임
- 화재경보에서 양성 = 실제 화재
세 경우 모두 양성은 "찾아내야 할 나쁜 사건"이다. 양성/음성은 가치 판단이 아니라 어느 쪽이 우리의 표적인가를 정해 두는 이름표라고 기억하자. 이 약속을 깔고, 이제 분류기가 실제로 어떻게 결정을 내리는지 그 속을 들여다보자.
0-2. 점수와 임계값과 예측 — ROC 전체의 씨앗
분류기는 사실 "예/아니오"를 바로 말하지 않는다
직관적으로는 분류 모델(분류기, classifier)이 이메일을 보고 곧장 "스팸!" 또는 "정상!"이라고 외칠 것 같다. 하지만 거의 모든 현대 분류기는 그렇게 동작하지 않는다. 모델은 먼저 각 사례에 대해 "이게 양성일 가능성이 얼마나 되는가"를 나타내는 하나의 수를 매긴다. 이 수를 점수(score)라고 부른다. 점수는 0과 1 사이의 확률(예: 0.92 = "92% 양성 같다")일 수도 있고, 0~100점 같은 임의의 척도일 수도 있다. 중요한 것은 척도의 모양이 아니라 그 의미다. 점수가 높을수록 모델은 그 사례가 양성이라고 더 강하게 의심한다.
비유하자면, 점수는 의사가 "이 환자, 한 70%쯤 병이 의심되네요"라고 말하는 확신의 세기와 같다. 의사는 아직 "병이다/아니다"를 단정하지 않았다. 단지 의심의 정도를 수로 표현했을 뿐이다.
점수는 "순위"이지 아직 "결정"이 아니다
점수의 본질을 한 문장으로 못 박자. 점수는 사례들을 한 줄로 세우는 순위표일 뿐, 그 자체로는 어떤 결정도 아니다. 의사가 환자 열 명을 의심의 세기 순으로 줄 세웠다고 해서, 누구를 "환자"로 판정했는지는 아직 정해지지 않은 것과 같다.
그렇다면 순위표를 실제 "예/아니오" 결정으로 바꾸려면 무엇이 더 필요할까? 선을 하나 그어야 한다. "여기서부터 위는 양성, 아래는 음성"이라고 정하는 기준선 말이다. 이 기준선을 임계값(threshold)이라고 부른다. 규칙은 단순하다.
점수 ≥ 임계값이면 → 양성으로 예측, 그렇지 않으면 → 음성으로 예측.
이렇게 임계값을 적용해서 나온 최종 "양성/음성" 판정을 예측(prediction)이라고 한다. 정리하면 이런 흐름이다.
- 점수(score): 연속적인 수. 모델의 의심 세기. 순위.
- 임계값(threshold): 사람이 정하는 기준선. "이 선 위는 양성."
- 예측(prediction): 점수와 임계값을 비교해 나온 이진 판정. 결정.
왜 이 구분이 ROC의 씨앗인가
여기서 이 책 전체를 떠받치는 핵심 통찰이 나온다. 점수는 모델이 정하지만, 임계값은 사람이 자유롭게 옮길 수 있다. 같은 점수표를 그대로 두고 임계값만 위아래로 움직이면, 똑같은 모델에서 완전히 다른 예측이 쏟아진다. 임계값을 낮추면 더 많은 사례가 양성으로 판정되고, 높이면 더 적게 판정된다.
이 "임계값을 옮길 자유"가 바로 ROC 곡선이 태어나는 자리다. ROC는 한마디로 "임계값을 가능한 모든 위치로 옮겨 보면서 그때마다 분류 결과가 어떻게 변하는가"를 한 장의 그림으로 그린 것이다. 그러니 지금 이 점수(연속) ↔ 예측(이진)의 구분을 확실히 잡아 두면, 뒤에서 ROC가 나올 때 "아, 임계값을 옮긴 결과들을 모아 둔 거구나" 하고 자연스럽게 받아들일 수 있다.
아래 그림은 이 흐름 전체를 한눈에 보여 준다. 하나의 사례가 모델을 거쳐 점수를 받고, 임계값과 비교되어 예측이 되고, 그 예측이 정답과 맞춰져 혼동행렬의 한 칸으로 들어가는 여정이다.
위 그림은 한 사례가 모델 → 점수 → 임계값 비교 → 예측 → 혼동행렬로 흘러가는 분류 파이프라인 전체를 보여 준다.
그런데 이 그림의 맨 마지막 칸, "혼동행렬"이 아직 낯설다. 예측을 내렸으면 그것으로 끝일 것 같은데, 왜 또 표가 필요할까? 답은 단순하다. 예측이 맞았는지 틀렸는지를 채점해야 하기 때문이다. 이제 그 채점표인 혼동행렬로 넘어가자.
0-3. 혼동행렬 — 예측을 채점하는 2×2 표
채점에는 두 가지 정보가 필요하다
예측 하나를 채점하려면 두 가지를 알아야 한다. ① 모델이 무엇이라고 예측했는가(양성/음성), 그리고 ② 실제 정답은 무엇이었는가(양성/음성). 두 질문 각각에 답이 둘씩 있으니, 둘을 곱하면 2×2 = 네 가지 경우가 생긴다. 이 네 경우를 칸으로 정리한 표가 혼동행렬(confusion matrix)이다. 이름이 "혼동"인 이유는 모델이 어디서 헷갈렸는지(confuse)를 보여 주기 때문이다.
표의 약속은 이렇다. 행(가로줄)은 실제 정답(양성/음성), 열(세로줄)은 모델의 예측(양성/음성)으로 둔다. 그러면 각 칸은 "실제는 ○인데 예측은 □"인 사례의 개수를 담는다.
네 칸의 이름과 그 작명 규칙
네 칸에는 각각 두 글자 이름이 붙는다. 이름은 두 부분으로 되어 있는데, 이 작명 규칙만 이해하면 네 이름을 외울 필요가 없다.
- 첫 글자 (True / False) = 모델이 맞혔는가? 예측이 정답과 같으면 True, 다르면 False.
- 둘째 단어 (Positive / Negative) = 모델이 무엇이라고 예측했는가? 양성 예측이면 Positive, 음성 예측이면 Negative.
이 규칙으로 네 칸을 풀어 보자.
| 이름 | 풀어 읽기 | 무슨 뜻인가 |
|---|---|---|
| TP (True Positive) | "맞게(True) 양성(Positive)이라 함" | 실제 양성을 양성으로 맞힘 |
| FP (False Positive) | "틀리게(False) 양성(Positive)이라 함" | 실제 음성인데 양성으로 잘못 판정 |
| FN (False Negative) | "틀리게(False) 음성(Negative)이라 함" | 실제 양성인데 음성으로 놓침 |
| TN (True Negative) | "맞게(True) 음성(Negative)이라 함" | 실제 음성을 음성으로 맞힘 |
여기서 흔히 막히는 지점이 하나 있다. FP와 FN을 헷갈리는 것이다. 작명 규칙으로 다시 풀어 보면 헷갈릴 일이 없다. 둘째 단어는 예측을 가리킨다. 그러니 False Positive는 "양성이라 예측했는데(P) 틀렸다(F)" → 실제로는 음성. False Negative는 "음성이라 예측했는데(N) 틀렸다(F)" → 실제로는 양성. 즉 틀린 칸의 이름은 예측한 쪽을 따른다. 이 한 줄만 기억하면 된다.
아래 그림은 네 칸이 실제·예측의 어느 교차점에 놓이는지를 보여 준다.
위 그림은 실제(양성/음성) × 예측(양성/음성)의 2×2 교차에서 TP·FP·FN·TN이 각각 어느 칸에 들어가는지를 나타낸다. 왼쪽 열(TP·FP)은 모델이 "양성"이라 예측한 칸, 오른쪽 열(FN·TN)은 "음성"이라 예측한 칸이다.
다음은 같은 네 칸을 실제 숫자가 들어간 히트맵으로 본 것이다. 칸의 색이 진할수록 사례 수가 많다는 뜻이다.
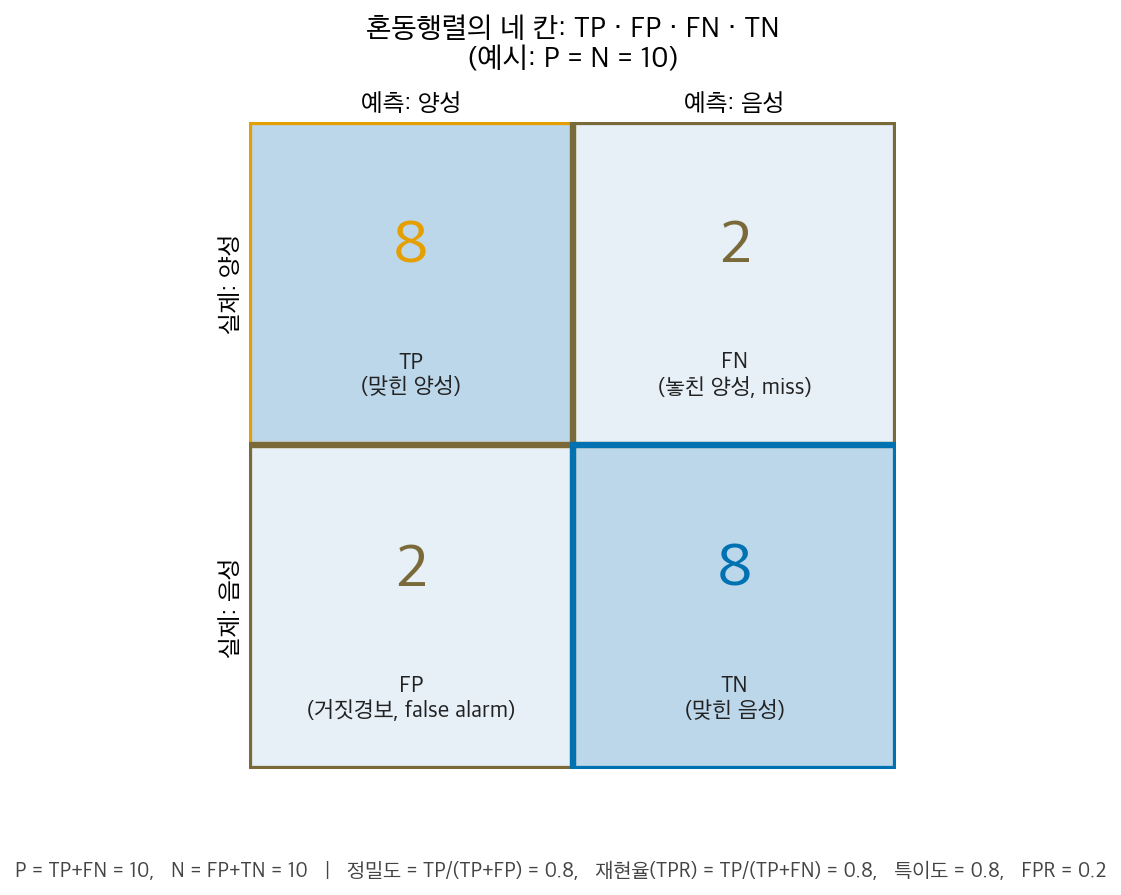
위 그림은 작은 예시(TP=8, FP=2, FN=2, TN=8)에 대해 2×2 혼동행렬의 네 칸을 라벨과 숫자로 함께 보여 주는 히트맵이다.
합으로 나오는 두 가지 전체 수: P와 N
네 칸을 더하면 전체 사례 수가 나온다. 그런데 그중에서도 특별히 자주 쓰는 두 합이 있다.
- 실제 양성의 총수: 실제로 양성인 사례는 TP(맞힌 것) + FN(놓친 것)뿐이다. 이 합을 P라고 쓴다. → P = TP + FN
- 실제 음성의 총수: 실제로 음성인 사례는 TN(맞힌 것) + FP(잘못 양성 판정한 것)뿐이다. 이 합을 N이라고 쓴다. → N = FP + TN
P와 N은 혼동행렬의 두 행의 합이다(행 = 실제). 이 P와 N은 뒤에서 비율을 계산할 때 분모로 계속 등장하니, "P는 실제 양성 전부, N은 실제 음성 전부"라고 새겨 두자.
이제 네 칸의 이름은 알았다. 하지만 이름만으로는 부족하다. 각 칸이 현실에서 어떤 의미를 갖는지, 어떤 칸이 무서운지를 몸으로 느껴야 한다. 비유로 넘어가자.
0-4. 네 칸을 몸으로 느끼기 — 세 가지 정확한 비유
추상적인 TP·FP·FN·TN을 현실의 이야기로 바꿔 보면 각 칸의 무게가 다르다는 것이 보인다. 세 가지 친숙한 상황으로 같은 네 칸을 비춰 보자. (비유는 강력하지만 위험하다. 틀린 비유는 오개념을 심으니, 아래 셋은 칸의 정의와 정확히 맞아떨어지는 것만 골랐다.)
비유 1 — 질병 검사 (양성 = 병이 있음)
병원에서 어떤 병을 검사한다고 하자. 양성 = "병이 있다"이다.
- TP: 병이 있는 사람을 양성으로 — 제대로 찾아냄. 좋다.
- TN: 건강한 사람을 음성으로 — 제대로 안심시킴. 좋다.
- FN (놓침, miss): 실제로 병이 있는데 음성이라 판정 — 병을 놓쳤다. 환자는 치료 기회를 잃는다. 가장 위험한 오류.
- FP (거짓 경보, false alarm): 건강한데 양성이라 판정 — 불필요한 추가 검사와 불안. 성가시지만 보통 FN보다는 덜 치명적.
이 비유에서 중요한 두 감각을 얻는다. 놓치지 않는 능력(FN을 줄이는 것)과 건강한 사람을 잘 거르는 능력(FP를 줄이는 것)은 서로 다른 미덕이라는 점이다. 이 두 능력에 곧 각각 이름(재현율·특이도)을 붙일 것이다.
비유 2 — 스팸 필터 (양성 = 스팸)
이메일에서 스팸을 거른다고 하자. 양성 = "스팸이다"이다.
- TP: 진짜 스팸을 스팸함으로 — 잘했다.
- TN: 정상 메일을 받은편지함에 — 잘했다.
- FP (거짓 경보): 정상 메일을 스팸함으로 잘못 보냄. 중요한 메일(합격 통보, 계약서)을 못 볼 수 있다 — 여기서는 이게 더 아프다.
- FN (놓침): 스팸이 받은편지함에 그대로 — 좀 성가시지만 직접 지우면 된다.
질병 검사와 비교해 보라. 여기서는 무서운 칸이 FN이 아니라 FP다. 즉 어떤 오류가 더 비싼지는 상황마다 다르다. 같은 네 칸인데도 맥락이 우선순위를 뒤집는다. 이 사실은 뒤에서 "임계값을 어디에 둘 것인가"를 정할 때 핵심 동기가 된다.
비유 3 — 화재경보 (양성 = 실제 화재)
건물의 화재경보기를 생각하자. 양성 = "진짜 불이 났다"이다.
- TP: 불이 났을 때 경보가 울림 — 제 역할.
- TN: 불이 안 났을 때 조용함 — 제 역할.
- FP (거짓 경보): 불도 안 났는데 울림 — 사람들이 대피하느라 번거롭고, 자꾸 울면 "양치기 소년"처럼 무시당한다.
- FN (놓침): 불이 났는데 안 울림 — 치명적. 사람이 다칠 수 있다.
화재경보에는 보통 민감도 다이얼이 있다. 다이얼을 민감하게(임계값을 낮게) 돌리면 연기만 조금 나도 울려서 FN(놓침)이 줄지만 FP(거짓 경보)가 는다. 둔감하게(임계값을 높게) 돌리면 반대가 된다. 이 다이얼이 바로 임계값이다. 0-2에서 말한 "임계값을 옮길 자유"가 현실에서 어떤 느낌인지를 이 다이얼이 정확히 보여 준다 — 그리고 다음 장(01)의 주제가 바로 이 다이얼을 돌릴 때 네 칸이 어떻게 변하는가다.
세 비유를 관통하는 결론은 이렇다. 네 칸은 단순한 개수가 아니라 서로 다른 무게를 가진 결과다. 그리고 어떤 칸을 줄이고 싶은지에 따라 우리는 모델의 성능을 서로 다른 비율로 측정하게 된다. 그 비율들을 이제 정의하자.
0-5. 네 칸에서 짜내는 네 가지 비율 — 정밀도·재현율·특이도·FPR
네 칸의 원시 개수만으로는 모델을 비교하기 어렵다. 어떤 데이터는 양성이 100개, 어떤 데이터는 5개일 수 있어서, "TP가 8개"라는 말은 전체 규모를 모르면 의미가 흐릿하다. 그래서 우리는 개수를 비율로 바꾼다. 비율은 "전체 중 얼마"인지를 말해 주므로 규모가 달라도 비교할 수 있다. 핵심 비율은 네 가지이며, 이들은 분모로 무엇을 쓰느냐에 따라 갈린다. 분모를 의식하며 읽으면 절대 헷갈리지 않는다.
(1) 재현율(Recall) = TPR = 민감도(Sensitivity) — "놓치지 않는 능력"
분모는 실제 양성 전부(P = TP + FN)다. 즉 "실제로 양성인 것들 중에서 모델이 양성으로 잡아낸 비율"이다. 질병 검사로 말하면 "실제 환자 중 몇 %를 찾아냈는가". 화재로 말하면 "실제 화재 중 몇 %에서 경보가 울렸는가". 그래서 재현율은 놓치지 않는 능력의 측정이다. 재현율이 높다 = 놓침(FN)이 적다.
이 비율은 분야마다 다른 이름으로 불린다. 모두 같은 값이다.
★ 동의어 못 박기: TPR(True Positive Rate) = recall(재현율) = sensitivity(민감도) — 이 셋은 완전히 같은 하나의 값이다. 책에 따라, 분야에 따라 부르는 이름만 다를 뿐이다. (통계·의학에서는 sensitivity, 정보 검색에서는 recall, ROC 분석에서는 TPR을 즐겨 쓴다.)
이름이 셋이나 되는 이유는 역사적인 것이니, 셋을 보면 "아, 같은 거구나" 하고 넘기면 된다. 이 동의어 관계는 ROC 곡선의 세로축이 무엇인지 이해할 때 결정적이다.
(2) 특이도(Specificity) — "건강한 사람을 잘 거르는 능력"
분모는 실제 음성 전부(N = FP + TN)다. "실제로 음성인 것들 중에서 모델이 음성으로 제대로 거른 비율"이다. 질병 검사로 말하면 "실제 건강한 사람 중 몇 %를 음성으로 옳게 판정했는가". 특이도는 재현율의 음성판 짝꿍이다. 재현율이 양성 쪽을 얼마나 잘 잡는지를 본다면, 특이도는 음성 쪽을 얼마나 잘 지키는지를 본다.
(3) FPR(False Positive Rate) = 1 − 특이도 — "거짓 경보를 내는 비율"
분모는 역시 실제 음성 전부(N)다. "실제로 음성인 것들 중에서 모델이 잘못 양성이라 외친 비율", 곧 거짓 경보율이다. 특이도와 FPR은 같은 음성들을 두고 정반대를 센다. 특이도는 옳게 거른 비율, FPR은 잘못 울린 비율이니, 둘을 더하면 항상 1이 된다.
★ 동의어 못 박기: FPR = 1 − specificity(특이도). 음성 전부 중 옳게 거른 비율(특이도)과 잘못 양성이라 한 비율(FPR)을 더하면 1이기 때문이다. ROC 곡선의 가로축이 바로 이 FPR이다.
(4) 정밀도(Precision) — "양성이라 외쳤을 때 그게 맞을 확률"
여기서 분모가 달라진다. 정밀도의 분모는 모델이 양성이라 예측한 전부(TP + FP)다. 위의 세 비율이 모두 실제 양성/음성을 분모로 삼은 것과 달리, 정밀도는 예측한 양성을 분모로 삼는다. 그래서 정밀도는 "모델이 '양성!'이라고 외친 것들 중에서 진짜로 양성이었던 비율"을 뜻한다. 스팸 필터로 말하면 "스팸함에 넣은 메일 중 진짜 스팸의 비율" — 즉 정상 메일을 잘못 가둔(FP) 일이 적을수록 정밀도가 높다.
흔한 오개념 — "정밀도와 재현율은 결국 같은 거 아닌가?"
입문자가 가장 자주 빠지는 함정이 정밀도와 재현율을 한 덩어리로 뭉뚱그리는 것이다. 둘은 완전히 다른 질문에 답한다. 차이는 오직 하나, 분모다.
| 측정 | 공식 | 분모가 무엇인가 | 던지는 질문 |
|---|---|---|---|
| 재현율(TPR) | TP / (TP + FN) | 실제 양성 전부 (P) | "진짜 양성들 중 몇 %를 잡았나?" (놓치지 않았나?) |
| 정밀도 | TP / (TP + FP) | 예측 양성 전부 | "양성이라 외친 것들 중 몇 %가 진짜였나?" (헛다리짚지 않았나?) |
같은 TP가 분자에 있지만 분모가 다르므로 둘은 다른 값이고, 서로 다른 실수를 벌한다. 재현율은 놓침(FN)을 미워하고, 정밀도는 거짓 경보(FP)를 미워한다. "분모가 다르다"는 이 한 가지 사실이 둘을 가른다. (재현율 vs 정밀도의 긴장은 뒤의 불균형 데이터 장에서 다시 크게 다룬다.)
이제 공식만 보아서는 손에 잡히지 않으니, 작은 숫자로 직접 계산해 보자.
0-6. 손으로 직접 계산해 보기
다음과 같은 작은 혼동행렬을 가정하자. 양성 10개, 음성 10개로 이루어진 데이터에서 모델이 이렇게 채점되었다고 하자.
| 구분 | 예측 양성 | 예측 음성 | 행 합 |
|---|---|---|---|
| 실제 양성 | TP = 8 | FN = 2 | P = 10 |
| 실제 음성 | FP = 2 | TN = 8 | N = 10 |
먼저 분모로 쓸 두 합을 확인하자. P = TP + FN = 8 + 2 = 10, N = FP + TN = 2 + 8 = 10. 이제 네 비율을 하나씩 계산한다. 과정을 빠뜨리지 말고 따라가 보자.
- 정밀도 = TP / (TP + FP) = 8 / (8 + 2) = 8 / 10 = 0.8 → "양성이라 외친 10개 중 8개가 진짜였다."
- 재현율(= TPR = 민감도) = TP / (TP + FN) = 8 / (8 + 2) = 8 / 10 = 0.8 → "실제 양성 10개 중 8개를 잡았다(2개는 놓침)."
- 특이도 = TN / (TN + FP) = 8 / (8 + 2) = 8 / 10 = 0.8 → "실제 음성 10개 중 8개를 옳게 걸렀다."
- FPR = FP / (FP + TN) = 2 / (2 + 8) = 2 / 10 = 0.2 → "실제 음성 10개 중 2개에서 거짓 경보를 냈다."
검산으로 동의어 관계를 확인하자. 특이도 + FPR = 0.8 + 0.2 = 1.0 → FPR = 1 − 특이도가 맞다. 또 이 깔끔한 예에서는 우연히 정밀도·재현율·특이도가 모두 0.8로 같지만, 이는 TP=TN, FP=FN인 대칭적인 행렬이라 그런 것일 뿐이다. 일반적으로는 분모가 다르므로 네 값이 제각각 다르게 나온다. 직접 한 칸씩 숫자를 바꿔 가며 계산해 보면 "분모가 다르면 값이 달라진다"는 감각이 손에 붙는다.
이 손계산이 별것 아닌 듯해도, 사실 우리는 방금 ROC 곡선 위의 점 하나를 만든 것이다. (FPR, TPR) = (0.2, 0.8)이라는 좌표 한 쌍. 다음 장에서 임계값을 옮겨 가며 이런 점을 여러 개 찍을 텐데, 그 점들을 이으면 ROC 곡선이 된다. 즉 지금 계산한 (FPR, TPR)이 곧 그림 위의 한 점이 되는 셈이다.
0-7. 이 장에서 챙긴 것, 그리고 다음 장으로
이 장에서 우리는 ROC라는 건물을 짓기 위한 토대를 깔았다.
- 점수 → 임계값 → 예측: 모델은 먼저 연속적인 점수(순위)를 매기고, 사람이 정한 임계값과 비교해 이진 예측을 만든다. 점수와 예측의 구분이 이 책 전체의 씨앗이다.
- 혼동행렬의 네 칸: TP·FP·FN·TN. 이름은 "맞혔나(T/F) + 무엇이라 예측했나(P/N)"로 풀린다. FP는 거짓 경보, FN은 놓침.
- 네 비율: 재현율(=TPR=민감도) = TP/P는 놓치지 않는 능력, 특이도 = TN/N은 거르는 능력, FPR = FP/N = 1−특이도는 거짓 경보율, 정밀도 = TP/(TP+FP)는 양성 예측의 적중률. 분모가 무엇이냐가 이들을 가른다.
- 두 개의 동의어 사슬: TPR = recall = sensitivity, 그리고 FPR = 1 − specificity. 이 둘은 ROC 평면의 세로축·가로축의 정체이므로 반드시 기억한다.
여기서 자연스러운 질문 하나가 남는다. 0-2에서 "임계값은 사람이 자유롭게 옮길 수 있다"고 했는데, 그 다이얼을 돌리면 혼동행렬의 네 칸은 정확히 어떻게 변할까? 임계값을 낮춰 더 관대하게 양성을 외치면 무엇이 늘고 무엇이 줄까? 다음 장 01 — 임계값과 혼동행렬에서, 점수 분포 위에 임계값이라는 수직선을 세워 두고 그것을 좌우로 밀어 보며 네 칸이 어떻게 재분배되는지를 눈으로 따라가 보자. 거기서 우리는 "공짜 점심은 없다"는, ROC 곡선의 진짜 심장을 만나게 된다.