불균형 데이터: ROC가 거짓말할 때, PR이 진실을 말한다
Contents
학습목표 — 이 장을 마치면 다음을 할 수 있다.
- 음성이 압도적으로 많을 때 FPR이 둔감해져 ROC가 낙관적으로 보이는 이유를 설명한다.
- 같은 데이터의 ROC 곡선과 PR 곡선을 비교하고, PR이 드러내는 약점을 분석한다.
- 유병률(prevalence)과 기준선(baseline)을 근거로 어떤 곡선을 쓸지 판단한다.
1000명 중 5명을 찾는 문제
지금까지의 예제들은 양성과 음성의 수가 엇비슷했다. 하지만 현실의 많은 중요한 문제는 그렇지 않다. 희귀 질병 진단, 사기 거래 탐지, 공정 결함 검출 — 이런 문제에서 우리가 찾으려는 양성은 아주 드물다. 1000명 중 환자가 5명, 10만 건 거래 중 사기가 몇 건. 이런 데이터를 불균형(imbalanced) 데이터라 부른다.
불균형이 왜 위험한지 가장 단순한 예로 시작하자. 1000명 중 진짜 환자가 5명뿐인 검사를 만든다고 하자. 게으른 모델 하나가 모두를 음성("건강함")이라고 찍는다. 이 모델의 정확도는 얼마일까? 995명을 맞히고 5명만 틀렸으니 99.5%다. 숫자만 보면 훌륭해 보인다. 그러나 이 모델은 환자를 단 한 명도 찾지 못한다 — 완전히 쓸모없다.
이것이 불균형 데이터의 함정이다. 다수 클래스(음성)의 바다가 지표를 익사시킨다. 정확도가 속았다면, ROC도 속을 수 있을까? 놀랍게도, 그렇다.
이 챕터는 ROC가 불균형에서 어떻게 우리를 과신하게 만드는지, 그리고 PR 곡선이 어떻게 현실을 되돌려 주는지를 다룬다.
왜 ROC는 불균형에서 낙관적인가
핵심은 FPR의 분모에 있다. 정의를 다시 불러오자(00 챕터).
FPR의 분모는 N, 곧 전체 음성의 수다. 그런데 불균형 데이터에서 N은 거대하다. 이 챕터에서 줄곧 쓸 구체적 데이터를 미리 꺼내 보자 — 양성 50명, 음성 약 950명(유병률 0.05, 즉 음성이 양성의 약 19배인 "19대 1" 데이터)이다. 분모 N이 이렇게 950에 이르면, 분자 FP가 꽤 늘어나도 FPR은 거의 움직이지 않는다.
숫자로 느껴 보자. 음성 약 950명 중 거짓경보가 50건 났다고 하자. 50건이면 결코 적지 않다. 그런데 FPR = 50 / 950 ≈ 0.05다. ROC 평면에서 보면 거의 왼쪽 끝에 붙어 있어 "거짓경보가 거의 없는" 좋은 운영점처럼 보인다. 거짓경보 50건이 950명이라는 거대한 분모에 희석되어 사라지는 것이다.
이것이 ROC의 낙관 편향이다. 음성이 압도적으로 많으면 FPR이 둔감해지고, ROC 곡선은 좌상단에 바짝 붙어 "이 분류기 훌륭하다"고 속삭인다. AUC도 덩달아 높게 나온다.
그렇다면 거짓경보 50건의 진짜 무게를 누가 보여줄까? 정밀도(precision) 다.
정밀도의 분모에는 거대한 N이 없다 — TP와 FP만 있다. 우리가 찾아낸 진짜 양성을 5명(TP)이라 하고 거기에 거짓경보 50명(FP)이 섞이면, 정밀도 = 5 / (5 + 50) ≈ 0.09다. "양성이라고 한 것 중 진짜는 9%뿐"이라는, 훨씬 냉정한 진실이다. 정밀도는 FP에 민감하기 때문에 거짓경보를 희석하지 않는다.
PR 곡선: 정밀도와 재현율의 그래프
정밀도가 진실을 드러낸다면, 그 정밀도를 임계값에 따라 그린 곡선이 바로 PR 곡선(Precision-Recall curve) 이다. ROC가 임계값마다 (FPR, TPR)을 찍었듯이, PR 곡선은 임계값마다 (recall, precision)을 찍어 잇는다.
- x축 = recall (= TPR = 재현율): 진짜 양성을 얼마나 잡았는가.
- y축 = precision (정밀도): 양성이라 한 것 중 진짜 비율은 얼마인가.
ROC와 PR은 둘 다 임계값을 스윕해 그리지만, 보는 각도가 다르다. ROC는 음성 쪽(FPR)을 보고, PR은 양성 예측의 순도(precision)를 본다. 그래서 불균형에서 둘의 메시지가 갈린다.
PR 곡선에서 또 하나 결정적으로 다른 것은 기준선(baseline) 이다. ROC에서 랜덤 분류기의 기준선은 대각선이고 AUC = 0.5였다. 그런데 PR 곡선의 랜덤 기준선은 0.5가 아니라 양성 유병률이다.
왜 그럴까? 아무 정보 없이 무작위로 양성을 찍으면, 그중 진짜 양성의 비율(정밀도)은 데이터 전체의 양성 비율과 같아진다. 양성 50명·음성 약 950명이면 유병률은 50/1000 = 0.05이고, 랜덤 분류기의 PR 곡선은 precision ≈ 0.05인 수평선이 된다. 유병률이 낮을수록 PR의 출발선 자체가 바닥에 깔린다 — 불균형이 심할수록 정밀도를 끌어올리기가 본질적으로 어렵다는 뜻이다.
PR 곡선 아래 면적도 한 숫자로 요약할 수 있는데, 이를 AP(average precision, 평균 정밀도) 라 부른다. ROC의 AUC에 대응하는, PR 쪽의 요약값이다.
같은 데이터, 두 얼굴: ROC vs PR
이제 같은 불균형 데이터를 ROC와 PR 두 렌즈로 동시에 보자. 양성 50명, 음성 950명(유병률 0.05)인 데이터에, 양성 점수가 음성보다 평균적으로 높은 좋은 분류기를 적용한다.
- ROC로 보면: ROC-AUC가 약 0.88로 나온다. "꽤 훌륭한 분류기"라는 인상이다. 앞서 본 대로, 거대한 음성 950명이 FPR을 희석해 곡선을 좌상단에 붙여 준 결과다.
- PR로 보면: 같은 분류기의 PR-AUC(AP)는 약 0.31에 그친다. 유병률 기준선 0.05보다는 분명히 높지만(즉 분류기가 랜덤보다 낫긴 하다), 0.88이 주던 자신감과는 거리가 멀다. "양성이라 한 것의 상당수가 여전히 거짓경보"라는 현실을 PR이 정직하게 보여준다.
같은 분류기, 같은 데이터인데 ROC는 0.88로 후하고 PR-AUC는 0.31로 박하다. 어느 쪽이 거짓말일까? 둘 다 정확히 계산된 값이다. 다만 묻는 질문이 다르다. ROC는 "음성을 음성으로 잘 거르는가"를 묻고, PR은 "양성이라 외친 것이 진짜 양성인가"를 묻는다. 양성이 드물어 운영 현장에서 정작 중요한 것이 후자라면, PR이 더 정직한 그림이다.
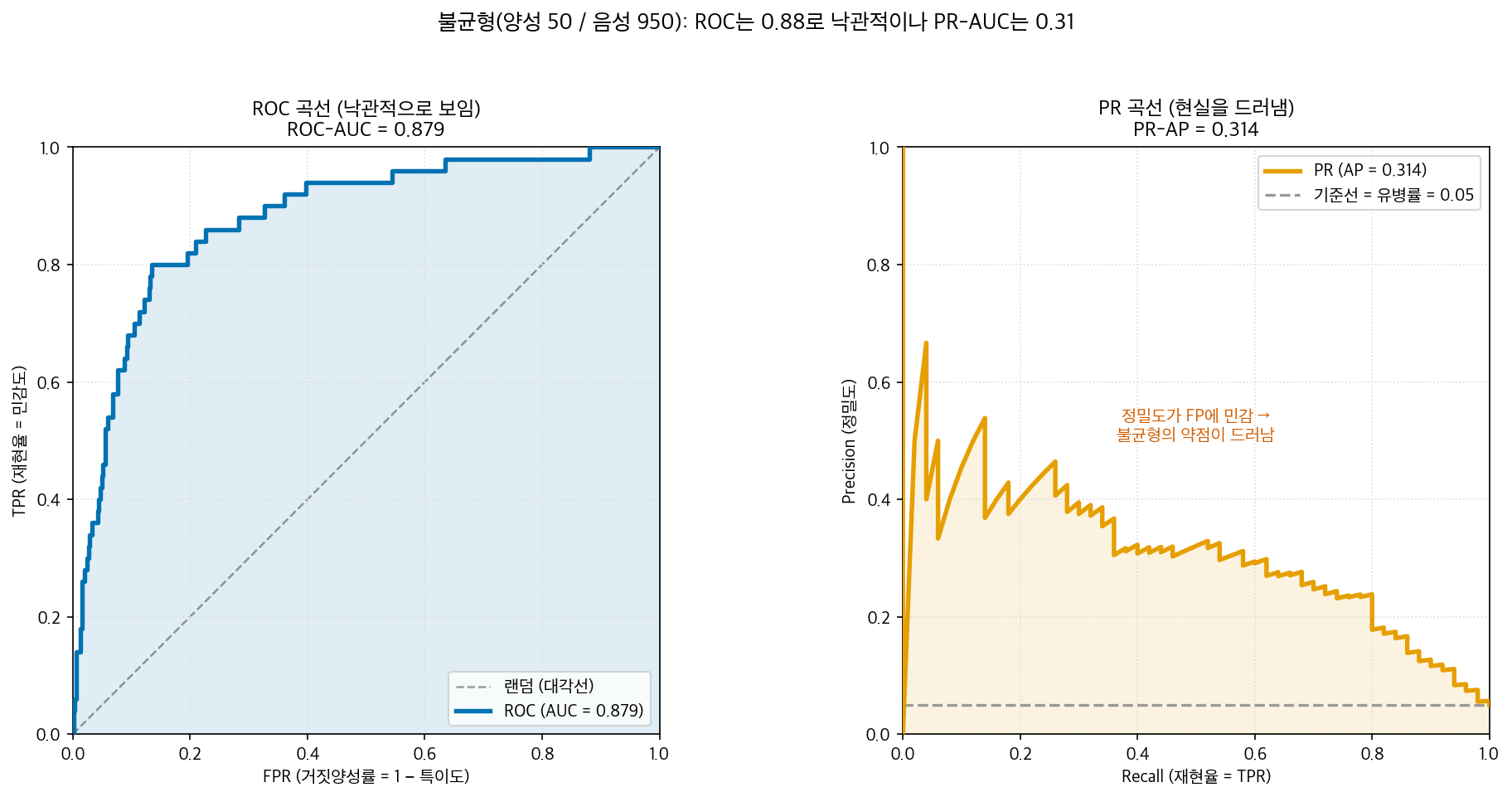
위 그림에서 왼쪽 ROC는 좌상단으로 시원하게 부풀어 좋아 보이지만, 오른쪽 PR은 곡선이 한참 아래에서 출발해 — 이것이 불균형의 민낯이다.
언제 ROC, 언제 PR
그렇다면 둘 중 무엇을 봐야 하나? 판단 기준은 유병률과 무엇이 중요한가이다.
- 양성과 음성이 엇비슷하다(균형 데이터) → ROC로 충분하다. FPR이 희석되지 않으므로 ROC와 PR이 비슷한 메시지를 준다.
- 양성이 드물다(불균형 데이터) 이고 양성 예측의 품질(정밀도)이 운영상 중요하다 → PR을 함께(또는 우선) 보라. ROC만 보면 과신하기 쉽다. 사기 탐지, 희귀병 진단, 정보 검색의 상위 결과 품질 등이 여기에 해당한다.
핵심 한 줄: ROC는 음성의 바다 덕에 관대해지지만, PR은 그 바다에 흔들리지 않고 양성 예측의 순도를 정직하게 잰다. 양성이 귀할수록 PR을 믿어라.
아래 그림은 "음성 다수 → FPR 둔감 → ROC 낙관"의 인과와, 그것을 PR이 어떻게 교정하는지를 보여준다.
불균형은 한 분류기를 잘못 평가하게 만드는 대표적 함정이다. 그런데 지금까지 우리가 다룬 것은 모두 양성/음성 두 클래스뿐이었다. 클래스가 셋 이상이면 ROC를 어떻게 그릴까? 다음 챕터 07 — 다중분류 ROC에서 다중분류로 확장한다.