AUC: 곡선 아래 면적
학습목표 — 이 장을 마치면 다음을 할 수 있다.
- AUC가 ROC 곡선 아래 면적임을 설명하고, 1.0·0.5·0.5 미만이 각각 무엇을 뜻하는지 해석한다.
- AUC의 확률적 해석 — 무작위로 고른 양성이 무작위로 고른 음성보다 높은 점수를 받을 확률(= Mann–Whitney U) — 을 정확히 진술한다.
- AUC와 정확도(accuracy)를 구분한다(AUC는 임계값과 무관한 순위 품질, 정확도는 한 임계값에서의 적중률).
곡선을 숫자 하나로 — 왜 면적인가
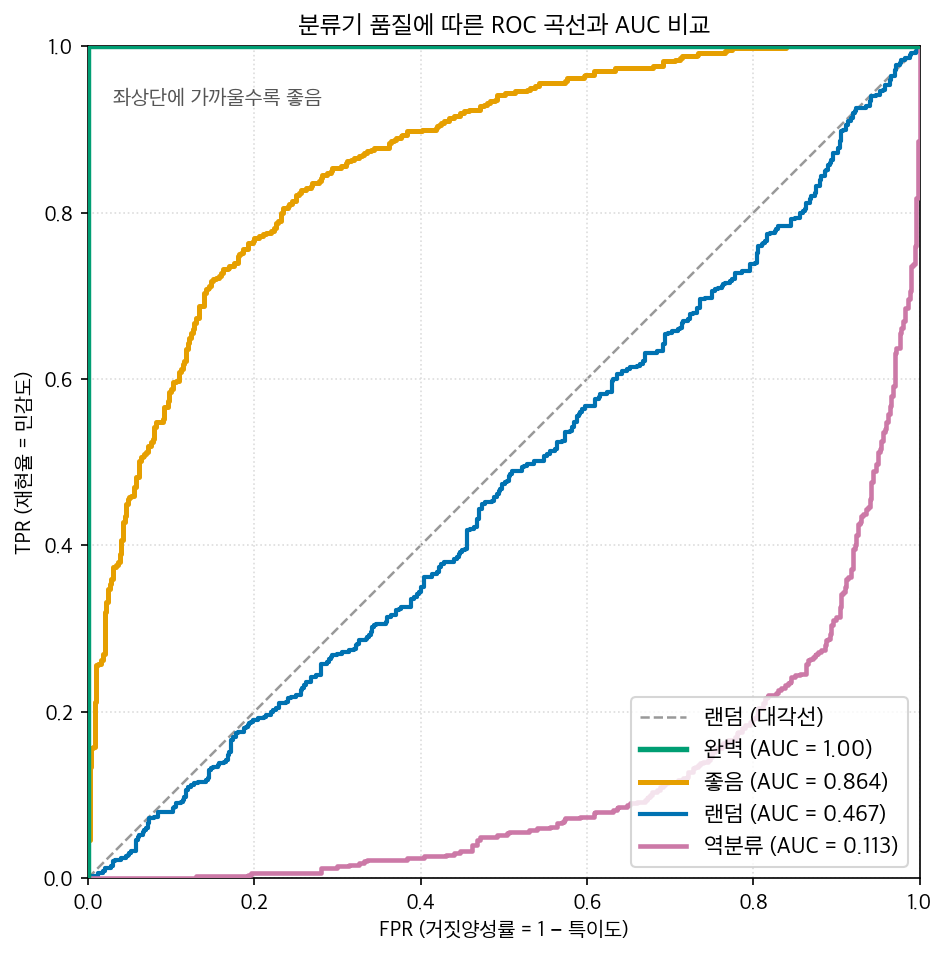
02장에서 우리는 ROC 곡선이 "좌상단에 가까울수록 좋다"는 것을 보았다. 그런데 곡선 두 개를 눈으로 비교하기는 번거롭고, 보고서에 "이 모델은 저 모델보다 곡선이 더 좌상단에 붙어 있습니다"라고 쓸 수도 없는 노릇이다. 우리에게 필요한 건 곡선의 좋음을 숫자 하나로 요약한 값이다.
그 요약값이 바로 AUC(Area Under the ROC Curve, ROC 곡선 아래 면적)다. 이름 그대로, ROC 평면에서 곡선 아래쪽(곡선과 x축 사이)의 넓이를 잰 값이다. ROC 평면은 가로·세로가 모두 0에서 1인 정사각형이므로, 그 안의 면적인 AUC도 0과 1 사이의 값을 갖는다.
면적이 곡선의 좋음을 잘 요약한다는 건 직관적으로 자연스럽다. 곡선이 좌상단 모서리에 바짝 붙으면 그 아래 면적이 정사각형 거의 전부(≈1)를 채우고, 곡선이 대각선을 따라가면 면적이 딱 삼각형 절반(=0.5)이 된다. 즉 곡선이 위로 부풀수록 면적이 커진다 — 좋은 분류기일수록 AUC가 1에 가깝다.
세 가지 기준점을 기억해 두면 어떤 AUC 값을 보든 즉시 감을 잡을 수 있다.
- AUC = 1.0 → 완벽한 분류기. 곡선이 좌상단 (0,1)을 지나며 정사각형을 가득 채운다. 양성과 음성의 점수가 완전히 갈렸다는 뜻.
- AUC = 0.5 → 무작위(동전 던지기). 곡선이 대각선과 겹쳐 삼각형 절반만 채운다. 점수에 양·음을 가르는 정보가 전혀 없다.
- AUC < 0.5 → 역분류. 곡선이 대각선 아래로 처진다. 순위 정보가 거꾸로 붙어 있다는 뜻(뒤에서 자세히).
면적이라는 기하학적 그림은 직관적이지만, AUC의 진짜 매력은 이 면적이 동시에 확률을 뜻한다는 데 있다. 이 놀라운 일치가 다음 절의 주제다.
AUC의 확률적 해석 — 가장 중요한 한 문장
AUC를 깊이 이해하는 열쇠는, 이 면적이 우연한 기하학적 양이 아니라 명확한 확률과 같다는 사실이다. 이 챕터에서 단 한 문장만 외운다면 이것이어야 한다.
AUC = P(무작위로 고른 양성 1개의 점수 > 무작위로 고른 음성 1개의 점수).
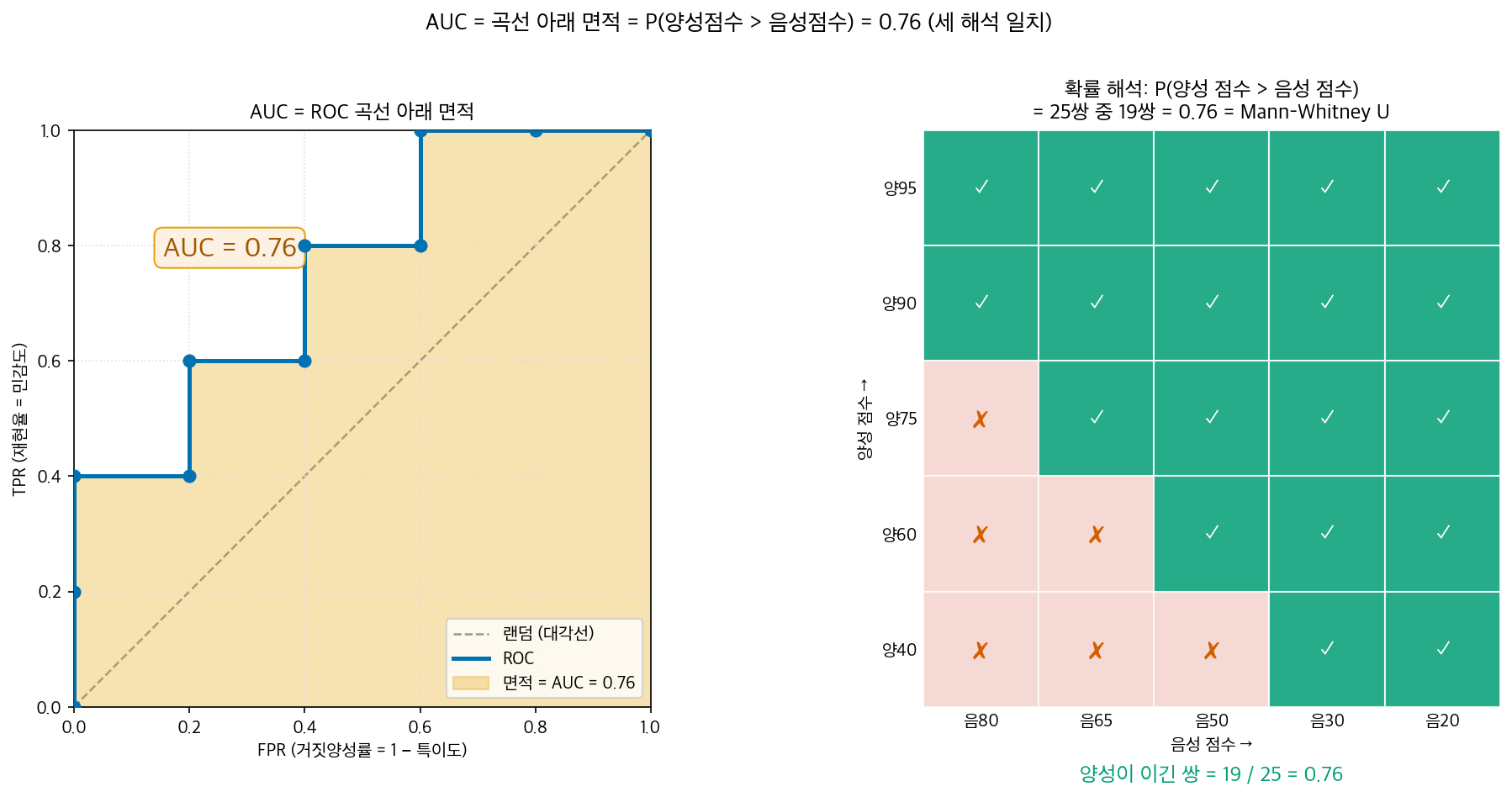
말로 풀면 이렇다. 양성 더미에서 아무거나 하나, 음성 더미에서 아무거나 하나를 꺼내 둘의 점수를 비교한다. 양성 쪽 점수가 더 높을 확률 — 그것이 곧 AUC다(점수가 같은 동점은 0.5로 센다). AUC가 0.76이라면 "양성에서 하나, 음성에서 하나 뽑아 점수를 견주면 76% 확률로 양성이 더 높은 점수를 받는다"는 뜻이다.
이 해석이 왜 그렇게 중요한가? AUC를 순위(ranking)의 품질로 보게 해 주기 때문이다. 좋은 분류기란 "양성에 음성보다 높은 점수를 주는" 분류기이고, AUC는 바로 그 순위가 올바를 확률을 직접 잰다. 임계값이 어디든 상관없다 — 우리는 점수의 절대값이 아니라 양성·음성의 상대적 순서만 보고 있기 때문이다.
이 확률은 통계학에서 이미 잘 알려진 양과 정확히 같다. 바로 Mann–Whitney U 통계량(= Wilcoxon 순위합 검정의 통계량)이다(Fawcett 2006). 두 집단의 값을 모두 섞어 순위를 매겼을 때 한 집단이 다른 집단보다 얼마나 위에 있는지를 재는 그 통계량이, 정규화하면 그대로 AUC가 된다. 그래서 "곡선 아래 면적"과 "양성이 더 높을 확률"과 "Mann–Whitney U"는 세 이름을 가진 한 값이다.
이 일치는 말뿐이 아니라 숫자로 검증된다. 04장에서 쓸 표준 예제데이터(양성 5개, 음성 5개)에서는 양성×음성 = 5 × 5 = 25쌍을 만들 수 있는데, 그중 양성 점수가 더 높은 쌍이 정확히 19개다. 따라서 확률 = 19/25 = 0.76이고, 이 값은 같은 데이터로 곡선 아래 면적을 사다리꼴로 적분한 값(역시 0.76)과 정확히 일치한다. 두 길로 가도 같은 0.76에 도착하는 이 일치를 04장에서 손으로 직접 확인할 것이다.
아래 그림은 면적 해석과 확률 해석을 한 장에 나란히 보여 준다.
확률 해석을 손에 쥐었으니, 이제 가장 흔한 오해 하나를 정면으로 다루자. AUC는 정확도가 아니다.
AUC ≠ 정확도 — 가장 흔한 혼동
입문자가 가장 자주 빠지는 함정은 "AUC가 높으면 정확도가 높은 거 아닌가?"라는 생각이다. 둘은 다른 질문에 답하는 다른 지표다. 이 구분은 이 교재 전체의 체크리스트 항목일 만큼 중요하다.
- 정확도(accuracy)는 하나의 임계값에서 잰다. 임계값을 정해 모든 사례를 양/음으로 가른 뒤, (TP + TN) / 전체로 계산한다. 즉 정확도는 "그 한 컷에서 몇 개나 맞혔나"이고, 임계값을 바꾸면 값이 달라진다.
- AUC는 모든 임계값을 가로지르는 순위 분리력이다. 곡선 전체가 이미 모든 임계값을 담고 있으므로, AUC는 임계값을 고르지 않아도 정의된다. 즉 AUC는 임계값과 무관한 요약이다.
비유하자면, 정확도는 "특정 셔터 속도로 찍은 사진 한 장의 선명도"이고, AUC는 "이 카메라가 빛을 순서대로 얼마나 잘 분해하는가"라는 렌즈 자체의 성능이다. 사진 한 장(임계값 하나)은 잘못 찍을 수 있어도 렌즈(순위 능력)는 좋을 수 있고, 그 반대도 가능하다.
이 차이가 실전에서 결정적으로 갈리는 곳이 불균형 데이터다. 1000명 중 환자가 5명뿐인 상황을 떠올려 보자. "전부 음성"이라고 찍기만 해도 정확도는 99.5%가 나오지만, 이 모델은 환자를 단 한 명도 못 찾으니 쓸모가 없다. 정확도는 다수 클래스만 맞혀도 부풀어 오르기 때문이다. 반면 AUC는 "양성이 음성보다 높은 점수를 받는가"라는 순위를 보므로 이런 눈속임에 쉽게 속지 않는다(이 불균형 문제는 06장에서 PR 곡선과 함께 깊이 다룬다). 요점은 분명하다 — AUC 한 줄과 정확도 한 줄은 서로 다른 말을 하고 있다.
마지막으로, 앞서 미뤄 둔 두 경계값 0.5와 0.5 미만의 뜻을 확률 해석으로 마무리하자.
0.5와 그 아래 — 무작위와 역분류
확률 해석을 손에 쥐면 0.5와 0.5 미만의 의미가 또렷해진다.
AUC = 0.5는 "순위 정보가 전혀 없음"을 뜻한다. 양성을 하나, 음성을 하나 뽑아 점수를 견줄 때 양성이 더 높을 확률이 정확히 반반(0.5)이라는 말이다. 이는 양성과 음성의 점수 분포가 완전히 겹쳐, 점수가 양·음을 가르는 데 아무 도움이 안 되는 상태 — 동전 던지기와 같다. ROC 평면에서는 곡선이 대각선과 겹친다.
AUC < 0.5는 "무능"이 아니라 "방향이 뒤집힘"을 뜻한다. 이 점이 입문자에게 의외다. 0.5 미만이라는 건 양성이 음성보다 낮은 점수를 받는 경향이 있다는 뜻 — 즉 모델이 순위를 거꾸로 매기고 있다는 신호다. 거꾸로 매긴다는 것 자체가 정보가 있다는 증거이므로, 점수를 그대로 반전(부호를 뒤집거나 1에서 빼기)하면 AUC는 1 − AUC가 되어 좋은 분류기로 되살아난다. 예컨대 AUC가 0.11인 모델은 점수를 반전하면 0.89짜리 좋은 분류기가 된다. 그래서 "0.5는 랜덤, 0.5 미만은 정보가 있으나 거꾸로 붙은 것"이라고 기억하면 된다(이 반전 트릭은 08장에서 다시 짚는다).
이제 면적·확률·정확도와의 차이까지 갖췄으니, 남은 일은 작은 데이터로 직접 손계산해 이 모든 게 맞아떨어지는지 두 눈으로 확인하는 것이다. 그것이 다음 04장이다.
정리
- AUC = ROC 곡선 아래 면적이며 0~1 범위다. 1.0 = 완벽, 0.5 = 무작위, 0.5 미만 = 역분류.
- AUC의 확률 해석(★): 무작위로 고른 양성이 무작위로 고른 음성보다 높은 점수를 받을 확률(동점은 0.5). 이는 Mann–Whitney U / Wilcoxon 순위합과 같은 값이다 — 면적·확률·통계량이 한 값의 세 얼굴.
- AUC ≠ 정확도. 정확도는 한 임계값에서의 (TP+TN)/전체로 임계값 의존, AUC는 모든 임계값을 가로지르는 순위 분리력으로 임계값 무관. 불균형 데이터에서 둘은 크게 갈린다.
- 0.5 = 순위 정보 없음(동전). 0.5 미만 = 순위가 거꾸로 → 점수를 반전하면 1 − AUC로 좋은 분류기가 된다.
- 표준 예제데이터에서 면적(사다리꼴)과 확률(쌍 세기)이 모두 0.76으로 일치하며, 다음 장에서 이를 손으로 확인한다.